Archives
Archive for the ‘Technology’ Category
September 25, 2010
Facilitating Research Collaboration with Google’s Online Tools
I’m researching at UBC with Professor Mary Chapman on a project to find as much of the work of Sui Sin Far / Edith Eaton as we possibly can, and wanted to share some of my knowledge around Google’s online collaboration tools and their potential usefulness for digital humanities research. I’d really welcome your comments on anything I’ll discuss here, and I’d love to know: would a Google group for all EMIC participants be a useful thing, in your opinion?
Unfortunately, I really can’t help you with the crucial part of this research: actually finding SSF’s writing. Mary is a cross between a super sleuth and some kind of occult medium, and has a process of finding leads that is as impressive as it is mystifying. Through her diligence and creativity, she’s found over 75 uncollected works by SSF, including mainly magazine fiction and newspaper journalism published all over North America.
This project has been going on for years; a dizzying number of different people have worked on various aspects of it. When I joined the project in April, multiple spreadsheets and Word documents (with many versions of each one) were the main tools for facilitating collaboration. Each RA seems to have had his or her own system for tracking details on the spreadsheets, so sometimes a sheet will say, for example, that all issues of a journal from 1901 have been checked, but need to be re-checked (for reasons not made clear!)
This represented a terrific opportunity for me, since like most literature students I’m by nature quite right-brained. Working with technology (primarily in the not-for-profit sector) has been a left-brain-honing exercise for me. My brain seems to be a bit like a bird: it flies better when both wings — the left and right halves — are equally developed.
Imposing some left-brain logic on all this beautiful right-brain intuition was actually a fairly straightforward task. First, I set a up a Google group so that current RAs would be able to talk to each other and to Mary:
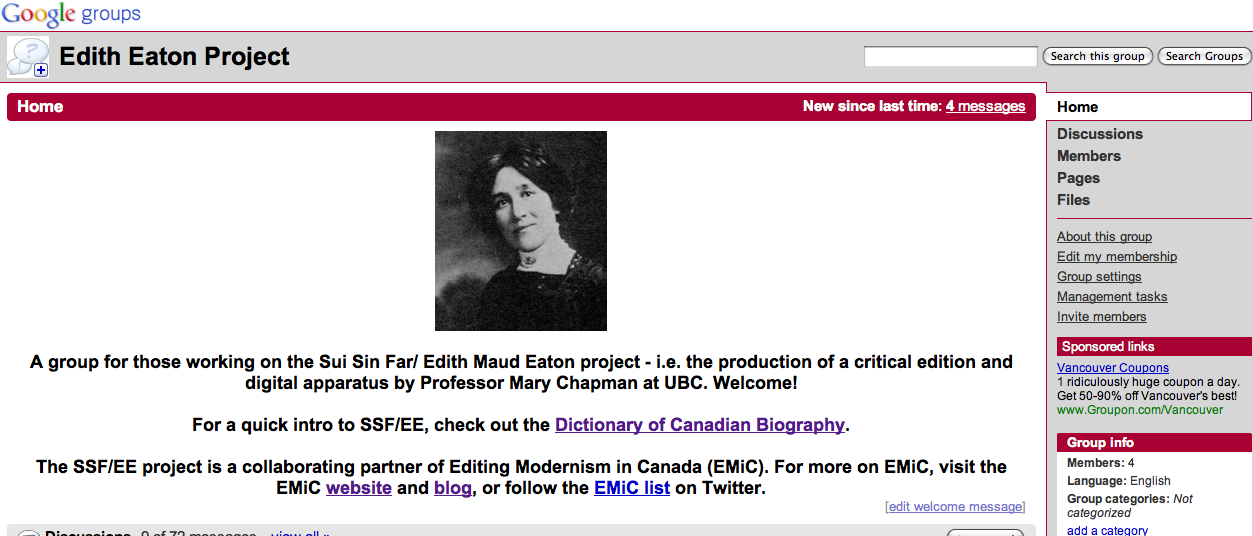
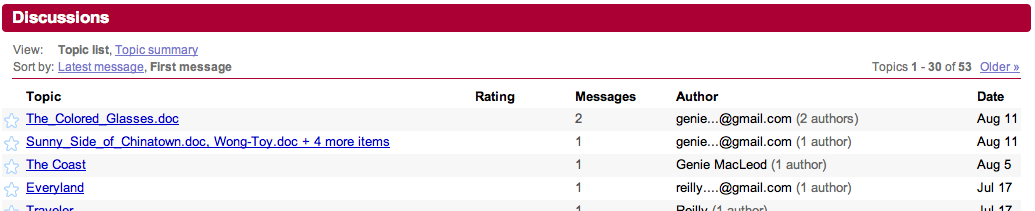
Creating a Google group gives you an email address you can use to message all members of the group. Then those emails are stored under “Discussions” in the group, leaving a legacy of all emails sent. This is an extremely useful feature – imagine being able to look back and track the thought process of all the people who proceeded you in your current role? It also prevents Mary from being the only brain trust for the project, and therefore a potential bottleneck (or more overworked than she already is).
I then created a series of Google spreadsheets, one for each of the publications we’re chasing down, from the Excel spreadsheets Mary had on her computer. I also created a template – this both sets the standard that each of our spreadsheets should live up to (i.e. lists the essential information, like the accession number, and the preferred means of recording who has checked which issues) and makes it very easy to set up spreadsheets for any publications we discover are of interest in the future.
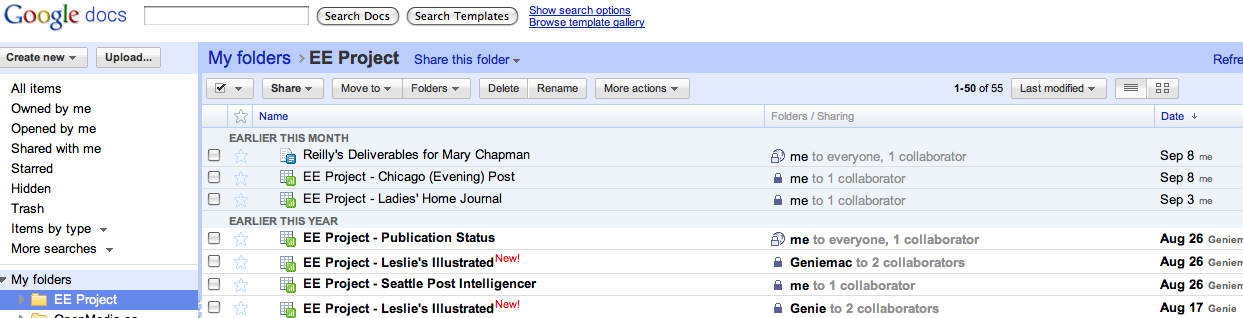
Finally, I created a master spreadsheet that tracks the status of all our research. More on how that works later on.
In my next post, I’d like to get into some of the specifics of how to use these tools, especially linking the documents to the group. I’d also really like to talk about the efficacy of this system, and the issues it raises: including the fact that, if any Google products (or Google itself) ever go Hal-3000 on us, we’re screwed.
~ Reilly
August 31, 2010
Fumbling for what we do not yet know
I recently finished reading Jerome McGann’s Radiant Textuality: Literature After the World Wide Web (2001), a text that documents McGann’s co-creation of The Rossetti Archive, a digital archive begun in 1993 and supported by The University of Virginia’s Institute for Advanced Technology in the Humanities (IATH). The first thing that struck me as incredible was that, although published nearly ten years ago, many of McGann’s concerns still remain of utmost concern for digital humanities today.
While the warning cries of downfall of the book that he documents as present back in 1993 are today echoed in heated debates surrounding e-readers and Google Books, McGann soothes these worries and asserts that the digital age will not bring about the death of the book but instead allow us a chance for critical reflection on the technology of the book. He asserts that a digital environment exponentially expands the critical possibilities of editorial projects such as The Rossetti Archive. “When we use books to study books,” he notes, “or hard copy texts to analyze other hard copy texts, the scale of the tools seriously limits the possible results” (55). That is, he sees traditional textual forms as “static and linear” in nature and digital forms as “open and interactive” and therefore able to move beyond the media of the primary text being studied in order to critically reflect with a broader and more elastic perspective. (25)
If we agree with McGann’s formulation of the static/linear versus open/interactive dichotomy of text and digital forms (Do we agree? Dichotomies are scary.) then what I want to start envisioning are editorial and critical projects that really do go beyond the formal limitations of the book. Here are some questions I’ve been throwing around:
1) What are the formal limitations of the book? Are these limitations truly dictated by the physicality of the book and all the ways we interact with it or are there psychological / social limitations that we have placed upon it? What are our reactions, to use a radical (but is it?) example, to an editorial method based around book burning. It seems abhorrent because of the social history of book burning but what possible textual illuminations (ha!) could such an editorial method produce? Maybe that’s a weird example, but what I want to start teasing out are the possible divisions between physical and social “limitations” of the technology of the book.
2) How can a digital environment help us to start such a project? How can studying the changes in text between these media broaden our understanding of the book? What would such studies look like? What sort of studies are already out there that attempt this?
3) Can we even start to project how such studies would then change the way we make and receive texts in both media? Do you believe McGann when he states that digital technologies allow for “interpretive moments” where not only do we discover “what we didn’t know we knew, we are also led into imaginations of what we hadn’t known at all” (129).
August 23, 2010
TEI & the bigger picture: an interview with Julia Flanders
I thought those of us who had been to DHSI and who were fortunate enough to take the TEI course with Julia Flanders and Syd Bauman might be interested in a recent interview with Julia, in which she puts the TEI Guidelines and the digital humanities into the wider context of scholarship, pedagogy and the direction of the humanities more generally. (I also thought others might be reassured, as I was, to see someone who is now one of the foremost authorities on TEI describing herself as being baffled by the technology when she first began as a graduate student with the Women Writers Project …)
Here are a few excerpts to give you a sense of the piece:
[on how her interest in DH developed] I think that the fundamental question I had in my mind had to do with how we can understand the relationship between the surfaces of things – how they make meaning and how they operate culturally, how cultural artefacts speak to us. And the sort of deeper questions about materiality and this artefactual nature of things: the structure of the aesthetic, the politics of the aesthetic; all of that had interested me for a while, and I didn’t immediately see the connections. But once I started working with what was then what would still be called humanities computing and with text encoding, I could suddenly see these longer-standing interests being revitalized or reformulated or something like that in a way that showed me that I hadn’t really made a departure. I was just taking up a new set of questions, a new set of ways of asking the same kinds of questions I’d been interested in all along.
I sometimes encounter a sense of resistance or suspicion when explaining the digital elements of my research, and this is such a good response to it: to point out that DH methodologies don’t erase considerations of materiality but rather can foreground them by offering new and provocative optics, and thereby force us to think about them, and how to represent them, with a set of tools and a vocabulary that we haven’t had to use before. Bart’s thoughts on versioning and hierarchies are one example of this; Vanessa’s on Project[ive] Verse are another.
[discussing how one might define DH] the digital humanities represents a kind of critical method. It’s an application of critical analysis to a set of digital methods. In other words, it’s not simply the deployment of technology in the study of humanities, but it’s an expressed interest in how the relationship between the surface and the method or the surface and the various technological underpinnings and back stories — how that relationship can be probed and understood and critiqued. And I think that that is the hallmark of the best work in digital humanities, that it carries with it a kind of self-reflective interest in what is happening both at a technological level – and it’s what is the effect of these digital methods on our practice – and also at a discursive level. In other words, what is happening to the rhetoric of scholarship as a result of these changes in the way we think of media and the ways that we express ourselves and the ways that we share and consume and store and interpret digital artefacts.
Again, I’m struck by the lucidity of this, perhaps because I’ve found myself having to do a fair bit of explaining of DH in recent weeks to people who, while they seem open to the idea of using technology to help push forward the frontiers of knowledge in the humanities, have had little, if any, exposure to the kind of methodological bewilderment that its use can entail. So the fact that a TEI digital edition, rather than being some kind of whizzy way to make bits of text pop up on the screen, is itself an embodiment of a kind of editorial transparency, is a very nice illustration.
[on the role of TEI within DH] the TEI also serves a more critical purpose which is to state and demonstrate the importance of methodological transparency in the creation of digital objects. So, what the TEI, not uniquely, but by its nature brings to digital humanities is the commitment to thinking through one’s digital methods and demonstrating them as methods, making them accessible to other people, exposing them to critique and to inquiry and to emulation. So, not hiding them inside of a black box but rather saying: look this, this encoding that I have done is an integral part of my representation of the text. And I think that the — I said that the TEI isn’t the only place to do that, but it models it interestingly, and it provides for it at a number of levels that I think are too detailed to go into here but are really worth studying and emulating.
I’d like to think that this is a good description of what we’re doing with the EMiC editions: exposing the texts, and our editorial treatement of them, to critique and to inquiry. In the case of my own project involving correspondence, this involves using the texts to look at the construction of the ideas of modernism and modernity. I also think the discussions we’ve begun to have as a group about how our editions might, and should, talk to each other (eg. by trying to agree on the meaning of particular tags, or by standardising the information that goes into our personographies) is part of the process of taking our own personal critical approaches out of the black box, and holding them up to the scrutiny of others.
The entire interview – in plain text, podcast and, of course, TEI format – can be found on the TEI website here.
August 3, 2010
Introducing: Anthologize!

The One Week | One Tool project, Anthologize, officially launched today at 12:30 ET, with 100+ people watching the live stream. I have say that I’m really impressed with the tool so far!
Below, I’ve compiled a list links to information, blogs, and groups pertaining to Anthologize (I will update as needed):
Official Sites
The Anthologize Homepage: http://anthologize.org/
Anthologize Google Group: http://groups.google.com/group/anthologize-users
The Official Launch Podcast: http://digitalcampus.tv/2010/08/03/episode-58-anthologize-live/
Cafe Press: http://www.cafepress.com/oneweekonetool
Blogs
Boone Borges: http://teleogistic.net/2010/08/introducing-anthologize-a-new-wordpress-plugin/
Dan Cohen, “Introducing Anthologize”: http://www.dancohen.org/2010/08/02/introducing-anthologize/
Dan Cohen’s Thoughts on One Week | One Tool: http://www.dancohen.org/2010/08/05/thoughts-on-one-week-one-tool/
Jana Remy: Daily Reports: 1 | 2 | 3 | 4 | 5 | 6 | Launch, or One Week | One Tool, Goes Live
Tom Scheinfeldt’s Lessons from One Week: Part 1: Project Management | Part 2: Tool Use | Part 3: Serendipity
Effie Kapsalis: Please Feed the Visitors | Smithsonian 2.0: Rapid Development at a 162 Year Old Institution
Kathleen Fitzpatrick: http://www.plannedobsolescence.net/anthologize/
Chad Black: http://parezcoydigo.wordpress.com/2010/08/03/anthologize-this-anthologize-that/
Mark Sample: http://www.samplereality.com/2010/08/04/one-week-one-tool-many-anthologies/
Anthologize at UMW: http://anthologize.umwblogs.org/
Julie Meloni @Profhacker: http://chronicle.com/blogPost/One-Week-One-Tool/25972
Patrick Murray-John: http://www.patrickgmj.net/blog/anthologize-uses-what-can-we-turn-on-its-head
Meagan Timney (My “Outsider’s Perspective”): http://corpora.ca/text/?p=422
News Items & Press
NEH Report:
http://www.neh.gov/ODH/ODHUpdate/tabid/108/EntryId/140/Report-from-ODH-Institute-One-Week-One-Tool.aspx
CUNY Commons: http://news.commons.gc.cuny.edu/2010/08/03/one-week-one-tool-the-reveal/
The Atlantic: http://www.theatlantic.com/science/archive/2010/08/academics-build-blog-to-ebook-publishing-tool-in-one-week/60852/
Musematic:
http://musematic.net/2010/08/03/anthologize/
Read-Write-Web: http://www.readwriteweb.com/archives/scholars_build_blog-to-ebook_tool_in_one_week.php
Chronicle Wired Campus: http://chronicle.com/blogPost/Digital-Humanists-Unveil-New/25966/
BookNet Canada Blog: http://booknetcanada.ca/index.php?option=com_wordpress&p=1787&Itemid=319
BBC Tech Brief: http://www.bbc.co.uk/blogs/seealso/2010/08/tech_brief_61.html
Snarkmarket: http://snarkmarket.com/2010/5979
Videos
Anthologize Test Drive by Ryan Trauman
—
I’ll finish with @sramsay‘s description of One Week | One Tool: “It was like landing on a desert island w/e.g. a master shipbuilder & someone who can start fires with their mind.” #oneweek
Please send additions and corrections to mbtimney.etcl@gmail.com or direct message @mbtimney
July 12, 2010
TEI @ Oxford Summer School: Intro to TEI
Thanks to the EMiC project, I am very fortunate to be at the TEI @ Oxford Summer School for the next three days, under the tutelage of TEI gurus including Lou Burnard, James Cummings, Sebastian Rahtz, and C. M. Sperberg-McQueen. While I’m here, I’ll be providing an overview of the course via the blog. The slides for the workshop are available on the TEI @ Oxford Summer School Website.
In the morning, we were welcomed to the workshop by Lou Burnard, who is clearly incredibly passionate about the Text Encoding Initiative, and is a joy to listen to. He started us off with a brief introduction to TEI and its development from 1987 through to the present (his presentation material is available here). In particular, he discussed the relevance to the TEI to digital humanities, and its facilitation of the interchange, integration, and preservation of resources (between people and machines and between different media types in different technical contexts). He argues that the TEI makes good “business sense” for the following reasons:
As a learning exercise, we will be encoding for the Imaginary Punch Project, working through an issue of Punch magazine from 1914. We’ll be marking up both texts and images over the course of the 3-day workshop.
After Lou’s comprehensive summary of some of the most important aspects of TEI, we moved into the first of the day’s exercises: an introduction to oXygen. While I’m already quite familiar with the software, it is always nice to have a refresher, and to observe different encoding workflows. For example, when I encode a line of poetry, I almost always just highlight the line, press cmd-e, and then type a lower case “L”. It’s a quick and dirty way to breeze through the tedious task of marking-up lines. In our exercise, we were asked to use the “split element” feature (Document –> XML Refactoring/Split Element). While I still find my way more efficient for me, the latter also works quite nicely, especially if you’re using the shortcut key (visible when you select XML Refactoring in the menu bar).
Customizing the TEI
In the second half of the morning session, Sebastian provided an explanation of the TEI guidelines and showed us how to create and customize schemas using the ROMA tool (see his presentation materials). Sebastian explained that TEI encoding schemes consist of a number of modules, and each module contains element specifications. See the WC3 school’s definition of an XML element.
How to Use the TEI Guidelines
You can view any of these element specifications in the TEI Guidelines under “Appendix C: Elements“. The guidelines are very helpful once you know your way around them. Let’s look at the the TEI element, <author>, as an example. If you look at the specification for <author>, you will see a table with a number of different headers, including:
<author>
the name of and description of the element
Module
lists in which modules the element is located
Used By
notes the parent element(s) in which you will find <author>, such as in <analytic>:
<analytic>
<author>Chesnutt, David</author>
<title>Historical Editions in the States</title>
</analytic>
May contain
lists the child element(s) for <author>, such as “persName”:
<author persName=”Elizabeth Smart”>Elizabeth Smart</author>
Declaration
A list of classes to which the element belongs (see below for a description of classes).
Example and Notes
Shows some accepted uses of the element in TEI and any pertinent notes on the element. On the bottom right-hand side of the Example box, you can click “show all” to see every example of the use of <author> in the guidelines. This can be particularly useful if you’re trying to decide whether or not to use a particular element.
—
TEI Modules
Elements are contained within modules. The standard modules include TEI, header, and core. You create a schema by selecting various modules that are suited to your purpose, using the ODD (One Document Does it all) source format. You can also customize modules by adding and removing elements. For EMiC, we will employ a customized—and standardized—schema, so you won’t have to worry too much about generating your own, but we will welcome suggestions during the process. If you’re interested in the inner workings of the TEI schema, I recommend playing around with the customization builder, ROMA. I won’t provide a tutorial here, but please email me if you have any questions.
TEI Classes
Sebastian also covered the TEI Class System. For a good explanation what is meant by a “class”, see this helpful tutorial on programming classes (from Oracle), as well as Sebastian’s presentation notes. The TEI contains over 500 elements, which fall into two categories of classes: Attributes and Models. The most important class is att.global, which includes the following elements, among others:
@xml:id
@xml:lang
@n
@rend
All new elements are members of att.global by default. In the Model class, elements can appear in the same place, and are often semantically related (for example, model.pPart class comprises elements that appear within paragraphs, and the model.pLike class comprises elements that “behave like” paragraphs).
We ended with an exercise on creating a customized schema. In the afternoon, I attended a session on Document Modelling and Analysis.
If you’re interested in learning more about TEI, you should also check out the TEI by Example project.
Please email me or post to the comments if you have any questions.
July 6, 2010
THATCamp London: Day 1
**Cross-posted from my blog.**
Today is the first day of THATCamp London, and I can already feel my inner geek singing with joy to be back with the DH crowd. In the pre-un-conference coffee room, I met up with some friends from DHSI (hello Anouk and Matteo!). Here are my “written on the fly” conference notes (to borrow from Geoffrey Rockwell’s methodology for his DHSI conference report):
– We begin in a beautiful lecture hall, the KCL Anatomy Theatre and Museum. I already feel the intellectual juices flowing.
– Dan Cohen provides introductions and a history of THATCamp. Notes that unstructured un-conferences can be incredibly productive. (We are creating, synthesizing, thinking). He recalls that the first THATCamp was controlled chaos.
– Dan setting some ground rules. He is adamant, “It’s okay to have fun at THATCamp!” (Examples: A group at one THATCamp who played ARG with GPS, another created robotic clothing!)
– We are asked to provide a 30 second to 1 minute summary of the proposals before we vote. Other sessions are proposed as well. Looks like a great roundup.
Sessions related to my own research that I am interested in attending:
– social tools to bring researchers and practitioners together
– living digital archives
– Participatory, Interdisciplinary, and Digital
– critical mass in social DH applications
– visualization
In my mind, the winner of the best topic/session title is “Herding Archivists.”
The beta schedule of the conference is now up: http://thatcamplondon.org/schedule/
Session 1: Data for Social Networking
The main questions and ideas we consider:
– What kind of methods/tools are people using for analysing data?
– Ethical issues in data collection and gathering?
– How do you store ‘ephemeral’ digital content
– What do we want to find out from our social network data?
– What Tools for Social Network Interrogation and Visualization?
– Our wishlist for working with social network data …
You can also check out the comprehensive Google Doc for the session.
Session 2: Stories, Comics, Narratives
– Major issues: 1) Standards, 2) Annotation, 3) Visualization
– narratives and semantic technologies
– difficulty of marking up complex texts such as comic books, tv shows
– Dan Cohen, how might we go about standardizing or making available different documents? Is markup always the answer?
– One participant asks, does it matter what format the document is in as long as the content is there?
– Once again, standardization is a key question. Once the data is collected, shouldn’t it be made available?
– Question of IP and copyright is also raised, and generates some heated discussion.
– “Semantic Narratives” and the BBC’s Mythology Engine.
Session 3: Digital Scholarly Editions
– A productive round-table on the future of the digital scholarly edition.
– Major issues: standardization, resources, audience
For discussion notes, please see the Google Doc for the session.
Session 4: Using Social Tools for Participatory Research Bringing Researchers and Practitioners Together
– Framework for academics to connect
-Finding connections, drawing on enthusiasm and community: http://en.logilogi.org/#/do/logis and http://www.londonlives.com.
– We need tools that collate information and resources
See the Google Doc for the session.
All in all, it was a very productive day.
—
And just for fun: Doctor Who Subtitle Search (Thanks, Anouk!)
June 28, 2010
Downtime: editingmodernism.ca
UPDATE: Both http://editingmodernism.ca and http://www.editingmodernism.ca are going to be down for the next 24 hours or so. You can still view the site at: http://lettuce.tapor.uvic.ca/~emic
-admin
June 21, 2010
Website Maintenance and Domain Name Migration
Just a heads up that we may be experiencing some downtime in the next few days as I change the nameserver entry to point to editingmodernism.ca. For those of you who may go through withdrawal, I encourage you to use our twitter hash tag (#emic) even more than usual! 
June 21, 2010
nuancing editions
The past week has been a great chance to settle back into life in Halifax (I trust many of you have received emails from EMiC HQ with updates on travel subventions and all that fun stuff) but it has also been a great chance to spend some time digesting and reflecting upon everything I learned and experienced at DHSI. I had a great meeting with Dean and got him caught up on the week’s activities and he mentioned how connected he felt to all of us because of this blog. With that in mind, I want to follow in Melissa and Meg’s footsteps and ensure that we continue to connect through the blog. As we talked about at our Friday wrap-up meeting, we also want to put into place a more standardized system of posting, so that each partner institution has a “turn” taking responsibility to post each week in order to keep this space vital, relevant, and interactive. We are going to draw up a schedule on this end of things but in the meantime if anyone has any suggestions I’d love to hear them! As a final “teaser,” we have designated one hour per week as time for our undergraduate and graduate interns here at Dal to use this “blog” to report on the work they’ve been doing this year– so stay tuned!
One of the things that Dean mentioned he’d love to see more of is people blogging about their specific projects. What projects did we go into DHSI with? Were there specific issues that you went into the course with? What issues came up during your class that may have changed the way you foresee conducting your research?
Here is my “for example.” As I’ve mentioned a few times, I went into the TEI fundamentals course with very little knowledge of anything remotely HTML or XML related, so I brought in simply curiosity as to how learning such languages may affect the way I operated as an editor. As I’ve been working with Elizabeth Smart’s novel By Grand Central Station I Sat Down and Wept, most of my editorial decisions have been based in the editorial theory I learned in Dean’s classes over the years on editions, small presses, and the history of editing practices in Canada. One thing I did not foresee before DHSI was how so many of the self-same editorial theory applies over to coding. The issue of “intentionalist editing,” as just one example, is just as pertinent to those working on digital editions as it is to those working on print editions. I started to become quite fascinated by the changing power-dynamics between the author, editor, and reader in any digital edition and questions of how playful or malleable our new tools make the text are simultaneously exciting and troubling.
The following is an example of an editorial issue that had been sitting on the sidelines of my brain until the TEI course brought it into clear focus:
One of the challenges and joys of working with an author like Elizabeth Smart is the allusive (and thereby elusive) her text is. Metaphors and allegories develop, weave, disappear, morph, and reappear at every turn of phrase or page. One of the extended tropes in By Grand Central Station is that of sacrifice, a trope expressed at times with references to Jesus and at others to the “wandering five million”–the displaced Jewish peoples of war-torn Europe. How does an editor footnote or tag these references? Does one write a detailed critical introduction outlining these issues and then noting whenever they show up? Does one build a narrative through end-notes that accumulates as the reader goes through? When does an editor draw a line between noting a reference? How does one deal with moments in the text which may be interpreted as fitting within a particular reading of the text? These are all issues I have been wrestling with over the years and I found that self-same issue at play in my TEI project.
On the first page of Smart’s novel we find the following paragraph (image is a scanned first-edition of the text):

The section I have issue with is “her madonna eyes, for as the newly-born, trusting as the untempted.” How does one footnote or tag a phrase such as this? First of all “madonna” is not capitalized and therefore I argue that it takes away from the authority of a reference to the Biblical reference. These eyes are “soft as the newly-born,” and such a reference to birth directly after “madonna” suggests to me the first of many references to Jesus in the text. To make it even more complex is the secondary reference to “the untempted.” Smart describes the eyes that belong to the wife of the man the narrator is planning to have an affair with as “trusting” as one who has never been tempted, but how does one read that in reference to Jesus, a figure who was repeatedly tempted? There are a number of interpretations for a section of prose such as this, but where does the onus lie for the editor to make note of such interpretive possibilities? Particularly in a scholarly edition? For the TEI mark-up I chose to tag the text as such:
{kind=link}

With the following notes appearing in the “back matter”:
{kind=link}

I’m not entirely happy with the results. The challenge that I ended up leaving DHSI considering is how we can possibly build a framework to accommodate for nuance in our texts. I would love to discuss how such nuance challenges us not only as scholars but as editors. How can our new editorial tools help us address such nuance? Could these tools possibly allow for an editorial apparatus that skillfully allows us to navigate or negotiate these nuances? In what ways could they allow for multiple co-existing interpretations? How does a more participatory relationship between reader and text by virtue of such tools allow for a co-existentially nuanced editorial practice?
June 17, 2010
Summary of EMiC Lunch Meeting, June 11, 2010
On the final day of DHSI, EMiC participants gathered for an informal meeting to discuss their summer institute experiences and to plan for the upcoming year. Dean and Mila attended via Skype (despite some technical difficulties). We began by going around the table and talking about our week at DHSI. We reviewed the courses that we took, discussed our the most helpful aspects, and least. The participants who had taken the TEI FUNdamentals course agreed that the first few days were incredibly useful, but that the latter half of the course wasn’t necessarily applicable to their particular projects. Dean made the comment that we should pick the moments when we pay attention, and work on our material as much as possible. Anouk noted the feeling of achievement (problem-solving feedback loop), and her excitement at the geographical scope involved in mapping social networks and collaborative relationships as well as standard geographical locations. It sounds like everyone learned a lot!
We also agreed that there is a definite benefit in taking a course that also has participants who are not affiliated with EMiC; the expertise and perspective that they bring to the table is invaluable.
After our course summaries, we began to think about the directions in which we want to take EMiC. We discussed the following:
1. The possibility of an EMiC-driven course at DHSI next year, which I will be teaching in consultation with Dean and Zailig
a. The course will likely be called “Digital Editions.”
b. It will be available to all participants at the DHSI, but priority registration will be given to EMiC partipants.
c. It will include both theoretical and practical training in the creation of digital editions (primarily using the Image Markup Tool), but also including web design and interface models.
d. We will develop the curriculum based on EMiC participants’ needs (more on this below).
2. Continued Community-Building
The courses provided us with ideas of what we want to do as editors, and allowed us to see connections between projects. The question that followed was how we will work with one another, and how we sustain discussion.
a. We agreed that in relation to the community, how we work together and what our roles are is very important, especially as they related to encoding and archival practice.
b. We discussed how we would continue to use the blog after we parted ways at the end of the DHSI. Emily suggested that we develop a formalized rotational schedule that will allow EMiC participants at different institutions to discuss their work and research. We agreed that we should post calls for papers and events, workshop our papers, and use the commenting function as a means of keeping the discussion going. (Other ideas are welcome!)
c. We discussed other ways to solidify the EMiC community, and agreed that we should set up EMiC meetings at the different conferences throughout the year (MSA, Congress, Conference on Editorial Problems, etc).
3. What’s next?
a. For those of you who are interested in learning more about text encoding, I encourage you to visit the following sites:
• WWP Brown University: http://www.wwp.brown.edu/encoding/resources.html
• Doug Reside’s XML TEI tutorial: http://mith2.umd.edu/staff/dreside/week2.html
b. We are hoping that there will be an XSLT course at the DHSI next year.
c. Next year’s EMiC Summer Institute line-up will include 3 courses: TEMiC theory, TEMiC practice, and DEMiC practice.
d. Most importantly, we determined that we need to create a list of criteria: what we need as editors of Canadian modernist texts. Dean requested that everyone blog about next year’s EMiC-driven DHSI future course. Please take 15-20 minutes to write down your desiderata. If you can, please come up with something of broad enough appeal that isn’t limited to EMiC. (Shout out to Melissa for posting this already!)
As a side note, I spoke with Cara and she told me that there is indeed going to be a grad colloquium next year, which will take place on Tuesday, Wednesday, and Thursday afternoon during the DHSI. Look for a call for papers at the end of summer.
It was lovely to meet everyone, and I am looking forward to seeing you all soon!
**Please post to the comments anything I’ve missed. kthxbai.