Archives
Archive for June, 2013
June 24, 2013
Hacking and Engineering: Notes from DHSI
A few weeks ago, at DHSI, I was giving a demo of a prototype I had built and talking to a class on versioning about TEI, standoff markup and the place of building in scholarship. Someone in the audience said I seemed to exhibit a kind of hacker ethos and asked what I thought about that idea. My on-the-spot answer dealt with standards and the solidity of TEI, but I thought I might use this space to take another approach to that question.
The “more hack less yack” line that runs through digital humanities discussions seems to often stand in for the perceived division between practice and theory, with those scholars who would have more of the latter arguing that DH doesn’t do cultural (among other forms of) criticism. That’s certainly a worthwhile discussion, but what of the division, among those who are making, between those who hack and those who do something else?
I take hacker to connote a kind of flexibility, especially in regards to tools and methods, coupled with a self-reliance that rejects larger, and potentially more stable, organizations. Zines. The command line. Looking over someone’s shoulder to steal a PIN. Knowing a hundred little tricks that can be put together in different ways. There’s also this little graphic that’s been going around recently (and a version that’s a bit more fun) that puts hacking skills in the context of subject expertise and stats knowledge. Here, what’s largely being talked about is the ability to munge some data together into the proper format or to maybe run a few lines of Python.
This kind of making might be contrasted with engineering—Claude Lévi-Strauss has already drawn the distinction between the bricoleur and the engineer, and I think it might roughly hold for the hacker as well. In short, the bricoleur works with what she has at hand, puts materials (and methods?) together in new ways. The engineer sees all (or more) possibilities and can work toward a more optimal solution.
Both the bricoleur and the engineer are present in digital humanities work. The pedagogical benefits of having to work with imperfect materials are cited, and many projects do tend to have the improvised quality of the bricoleur—or the hacker described above. But many other projects optimize. Standards like the TEI, I would argue, survey what is possible and then attempt to create an optimal solution. Similarly, applications and systems, once they reach a certain size, drive developers to ask not what do I know that might solve this problem but what exists that I could learn in order to best solve this problem.
My point here has little to do with either of these modes of building. It’s just that the term “hack” seems to get simplified sometimes in a way that might hide useful distinctions. Digital humanists do a lot of different things when they build, and the rhetorical pressure on building to this point seems to have perhaps shifted attention away from those differences. For scholars interested in the epistemological and pedagogical aspects of practice, I think these differences might be productive sites for future work.
June 13, 2013
Every Batman Needs a Robin

As a result of numerous discussions I have had this year at DHSI with EMiC scholars at all levels of experience—MA students, PhD students, postdocs, and profs from assistant to full, I have put together a proposal for a DHSI course next year. It has not been officially approved, but Ray and Dean are very interested in it and I will be discussing it with them next week.
I thought it would make sense to outline what the aim of this course—actually its double aim—is, and why I think it would be useful for many EMiC-scholars. It would be useful for my discussions with Ray and Dean if I had some sense of whether there is real interest in such a course.
The course would deal with 2 problems simultaneously:
- If you can’t do XSLT you can’t display your TEI documents—and you probably can’t do XSLT
- It is impossible to achieve mastery of XSLT or any other tool without spending so much time on it that you may have a negative impact on your career, especially if you are at the beginning of it.
The answers to these problems are 1) to develop enough basic familiarity with the tool you are interested in (such as XSLT, for example) so that you can discuss what you need with a developer partner—a week-long course at DHSI should be enough to do this—and 2) to develop a long-term working relationship with such a partner.
Some background first. I took the XSLT course from Syd and Martin and got a very good grounding in the basics. However, I was able to move on to the point where I can actually use XSLT in my project only because I happen to have a close working and personal relationship with an expert in the field, who happens to be my son. I know enough to write very basic XSLT, but, much more importantly ,I am familiar enough with the concepts and terminology that I can speak to my son and he can speak to me—and together we have produced some pretty sophisticated XSLT which does everything I want it to do. Because of my unusual situation I believe I am the only editor associated with EMiC who actually can work in XSLT—that is, who can turn my TEI files into web pages that people can actually read.
I have been aware of this very troubling situation for some time now. However, I became aware of something else at DHSI this year: everyone I know who is making real progress on their projects has a relationship between a humanist and a developer which is similar to my own. In each case the humanist/developer pair have enough of an understanding of each other’s fields to talk to each other and work together productively. Some examples: Dean Irvine & Alan Stanley and the Modernist Commons, Paul Hjartarson & Harvey Quamen and the Wilfred Watson project, Michael DiSanto & Robin Isard and the George Whalley project. Scholars who do not have such a working relationship seem to me to be in a high state of anxiety, especially graduate students and junior faculty. They feel that they have to acquire mastery of a range of tools while at the same time pursuing their research—when in fact what they really need to do is to acquire a basic understanding of their tools—such as a week-long course at DHSI can provide—PLUS a relationship with someone they can talk to and work with on an ongoing and well-informed basis concerning their plans and needs.
The course I am proposing would have as its aims to model the dynamics of such a relationship—with specific reference to XSLT—and to provide advice on how to develop it. You might compare the NetSquared project which has similar aims in relationship to social-benefit projects. We would begin by outlining the basics of XSLT; we would then go through in detail some of the XSLT we developed for use in the Digital Page project, while at the same time modelling the collaborative process that led to this development; finally we would help the students in the course to create their own XSLT to transform TEI files which they bring to the class. The takeaway for each student would be (1) XSLT files that would generate real HTML files for use in their editions and (2) guidance on how to establish the kind of ongoing working relationship that would result in the development of a wide range of more sophisticated XSLT files. We would invite other successful working partners to speak to (2) with regard to their own projects, and, indeed, in later years a course with a similar focus on collaborative digital humanities work could focus on entirely different aspects of digital humanities, such as databases, or interface design, for example. Taking our cue from Michael DiSanto & Robin Isard I am thinking of calling the course Every Batman Needs a Robin: A Collaborative Approach to XSLT.
A course of this sort will by necessity have limited enrolment—maybe 15—to allow for intensive hands-on mentoring. Because of the heavy emphasis on mentoring, we need to ensure that everyone has the appropriate basic skill set and has given serious thought to what they want their XSLT to produce. Therefore, everyone will be required to submit, before the course begins, 1) a text which they have already marked up in TEI and 2) a clear idea of how they would like it presented, perhaps in the form of a mock-up in Word. The more preparation the instructors can make leading up to the course the better.
If you think you would be interested in such a course, or if you have any suggestions please contact me at zpollock@trentu.ca. If you have a Robin, feel free to bring him or her along.
June 13, 2013
Reflections on DHSI 2013: Or How I Learned to Love Databases and Acronyms (“RoDHSIoHILLDA”)
Ramping up in the wake of Congress, this year’s Digital Humanities Summer Institute, or “DHSI” for the acronym-inclined, gathered an unprecedented number of scholars, students, and researchers for training in, you guessed it, the digital humanities. Thanks to support from the Editing Modernism in Canada project (“EMiC”), a course on Digital Humanities Databases was my home for the intensive five-day summer institute that punctuates class time with colloquium and unconference sessions.
Taught by Harvey Quamen, Jon Bath, and John Yobb, the Digital Databases class led us through project planning, MySQL coding (Structured Query Language), database building, and finally, database queries that enable you to ask specific research questions. In short, I mapped out and built a database on Canadian literary adaptations in five days (however minimally populated it may be). When organizing the structure of my database and its multiple tables, I found it very helpful to think of the connected tables as a sentence: there is usually a subject (e.g. person), verb (e.g. adapting), and object (e.g. source). As with literary work, I learned that too much repetition is a bad sign and that spelling counts; the latter was quite horrifying for someone like me who is codependent on autocorrect because there is no autocorrect or red underline to aid in spelling or typos. I also made sure to take advantage of the one-on-one help from Harvey and the Jo(h)ns.
Andrea Hasenbank—an EMiC Doctoral Fellow—introduced the class to a free, online website called “SQL Designer” that not only enabled me to map out nine inter-related tables but also created the MySQL commands. Although seemingly sent from the digital gods, it still requires a background in MySQL in order to understand how to use, navigate, and implement the Designer, but the first three days of the Digital Databases course covers many of the database-specific commands and related structures. For those interested in taking the course and/or trying out SQL Designer, I have a few tips from a novice’s perspective:
– Be sure to save the database design often; I saved mine in my browser under a unique name.
– There is a button that will create foreign keys for you (which link two tables together). At first, I typed in all the foreign keys myself before discovering that the Designer will create and appropriately name foreign keys in junction tables. (For those unfamiliar with databases yet, fret not, this jargon will be all too clear by the end of the course’s first day.)
– There were some glitches for me in the MySQL Code, such as the repetition of the “null” command and the addition of “primary key” commands in junction tables that included no primary keys. Also, be sure to erase the last comma in a list of commands before the closing bracket and/or semicolon.
– I needed to edit the generated MySQL commands in a text editor (such as Text Wrangler) before inputting it into Terminal.
Here is a sample draft of my database design in SQL Designer:
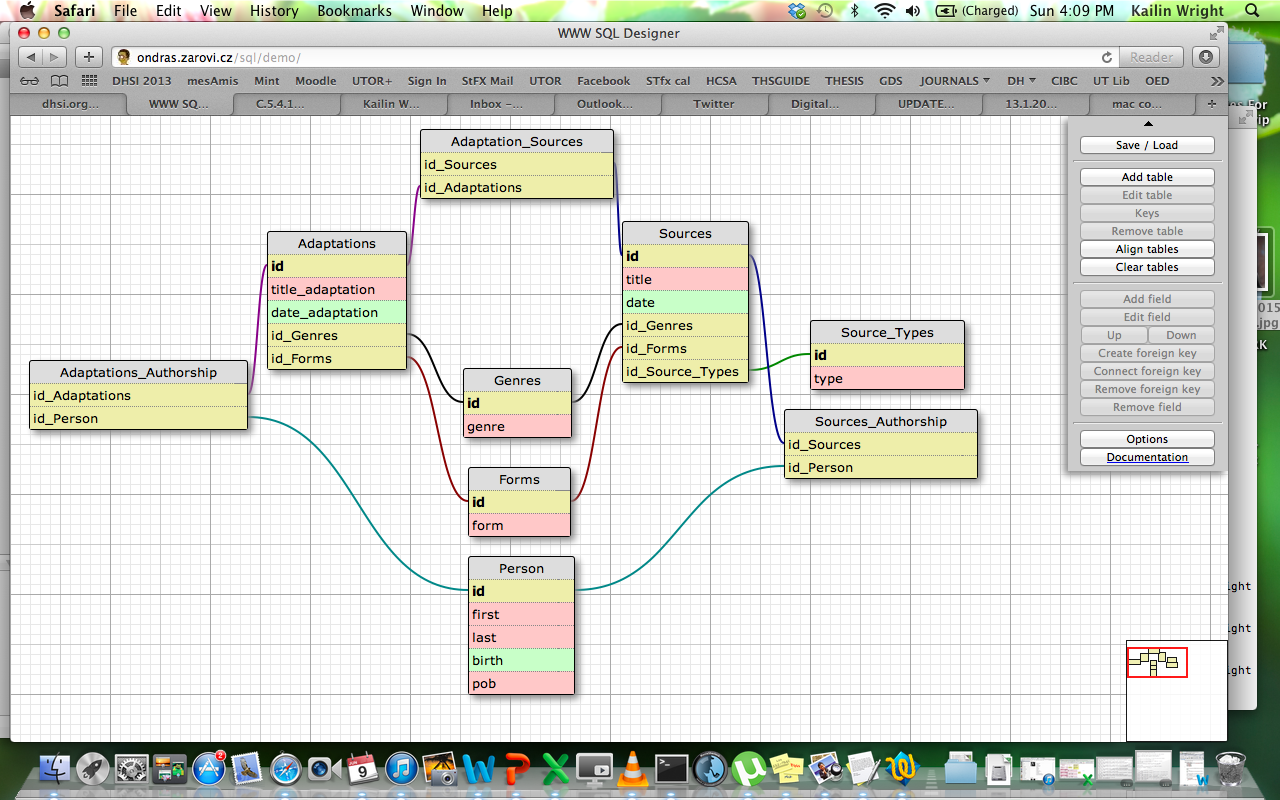
Kailin Wright Database Design in SQL Designer
You will notice that the SQL Designer can also encode the column type (primary id, date, foreign key, etc.).
My research investigates how Canadian literature rewrites popular narratives—Greek myth, Shakespearean plays, colonial legend, national histories—by changing the identities of marginalized characters. I examine Canadian revisionist plays that critique cultural figures like Philomela, Othello, and Pocahontas as reductive emblems of layered racial, sexual, and gendered identities. The digital Canadian Adaptations of Shakespeare Project, or if you haven’t had enough exciting acronyms, “CASP,” features an online database that has been integral to my research (Daniel Fischlin). Building on CASP, I am interested in creating a database that encompasses multiple sources and enables researchers or students to search Canadian adaptations of Greek mythology, the Bible, and Native mythology, to name a few. You could also, for instance, limit your search by author, date, and/or location that would list all the Canadian adaptations of Ovid, during post-WWI Canada, and/or in Nova Scotia. This database would help establish a wider field of Canadian adaptation studies.
The Digital Humanities Databases course cemented my appreciation of digital tools for literary scholarship . . . as well as my reliance on acronyms. Last but not least, thanks to the Databases course, I now understand why this is funny:
“Exploits of a Mom” comic strip is courtesy of xkcd.
June 8, 2013
DHSI2013: Susan Schreibman and the Versioning Machine
Early(ish) Saturday morning, the Versioning and Collation DHSI workshop had the opportunity to participate in a somewhat impromptu session with Dr. Susan Schreibman — the Long Room Hub Senior Lecturer in Digital Humanities in the Department of English at Trinity College Dublin and self-proclaimed representative of the “TEI police” — on her work developing the Versioning Machine.
Susan calls the Versioning Machine “a piece of software in a box designed for non-programmers.” On a most basic level, the software is meant to create editions online: users create single TEI documents which the Versioning Machine (using XSLT) separates into several other documents, or versions. No installations are required because transformations are on the client side of the application.
The Versioning Machine is very much a collaborative effort built by generations of literary scholars, designers, and developers. Admittedly, “the Versioning Machine” is a bit of a misnomer, because it isn’t really a “machine” — humans do the work, and the software displays the multiple versions of the text.
In developing this program, Susan and her team were and continue to be very concerned with the ethics of versions. What do we privilege? What constitutes an “authoritative” version or edition? Therefore, a chief advantage of the Versioning Machine is that it does not require users to appoint a base text, which means that users do not have to privilege one text over another. In this way, the software offers literary scholars an alternative to the variorum, as well as the opportunity to step back from the more traditional model which privileges the latest published version over earlier versions (for example, how we have viewed and taught the work of Yeats).
The future of the Versioning Machine is bright. For this coming year, Susan has secured funding for a postdoc who will be charged with further developing the software. At this point, however, Susan does not know what the Versioning Machine will look like after this postdoc. Daniel Carter from the Modernist Versions Project spent this past year working on the Versioning Machine, but he ultimately ended up versioning the software. Although the back end of Daniel’s version looks very different from the current version of the Versioning Machine, the front end is still very similar.
One of Susan’s main concerns in developing the Versioning Machine — both in the past and in future design — is the question of how to create “digital stuff that lasts.” It is no longer advisable to design with the two “p” words — perpetuity and proprietary — in mind; instead, Susan intends to create durable data that will last through future migrations. The TEI community, for example, has lasted because of its anticipation of what people will use based on what they are currently using; Susan envisions that kind of durability for the Versioning Machine.
June 3, 2013
The Long Now of Ulysses
How do new media forms change interpretations and representations of literature at a practical, exhibitionist level? This past spring, students in two graduate courses at the University of Victoria (The Modernist Novel and Intro to Digital Literary Studies) worked under the curatorial guidance of Stephen Ross and Jentery Sayers to figure that out.

Using James Joyce’s Ulysses as its point of reference, the resulting exhibit — The Long Now of Ulysses — combines digital and analogue media both to highlight passages of the text, and to tie those passages, as well as the novel’s themes and motifs in general, to contemporary events, places, etc. The exhibit, which inhabits physical space in the Maltwood Gallery located downstairs in McPherson Library and ethereal space via the Maker Lab website, blends the tangible with the abstract, and in doing so engages the various ways through which the text is mediated.

The Long Now of Ulysses did not arrive without its issues. After the first heady days of brainstorming possibilities which included smell, interactive sound, and a bucket of raw kidneys, the realities of labour and the space took precedence. Many of the co-curators had to become familiar with Ulysses (which is no minor task), while others had to learn new digital tools and procedures. Further, the Maltwood Gallery — although centrally located and attractively situated — shares space with the library, and more particularly, the graduate study carrels. Those concerns limited the auditory possibilities, and effectively curtailed the hoped-for olfactory exhibition.

A significant factor in all aspects of the exhibit has been — somewhat predictably — labour. Instead of including everything Ulysses, the co-curators have had to prioritize, and to cut out those things which are beyond the scope of time and labour. Fortunately, the central concepts, items, and projects have made it through unscathed, and are available for perusal in the exhibit.

The physical side of the Long Now of Ulysses exhibit is now on display in the Maltwood Gallery (downstairs in McPherson Library/Mearns Centre for Learning). Online components are accessible at the Maker Lab website — check it out before August 12.