Archives
Author Archive
June 12, 2011
Digital Editions @ DHSI: 2011 Version
This past week, I had the opportunity to teach a course on digital editions at the Digital Humanities Summer Institute with Matt Bouchard and Alan Stanley. It was my first time as an instructor at DHSI, and I was filled with nervous excitement on Monday morning. What I wanted to do with the course this year was to offer a holistic approach to building a digital edition that challenged the participants to think about their projects not only as a whole, but also as iterative and modular. The two themes that I tried to highlight were the importance of project management and the user-experience design. We talked quite a bit about planning and project management, workflow, information architecture, and for the first time, we worked with the alpha version of the Islandora editing toolkit.
All in all, I think the course went very well! Below are some of the highlights. I’ve included my classroom slides and handouts in the hopes that these materials will be useful for those who were unable to attend the course and who may be beginning to think about building a digital edition, and for anyone who is interested in what we were up to this week!
Day 1 Overview
On the first day we began with an overview of print editions, and talked a little bit about some of the benefits of text-based versus image-based digital editions. The class came up with quite a substantial list of the elements that comprise a print edition, including:
timlines/chronology
glossary
static pages
page numbers
running headers
marginalia
provenance
book cover
dust jacket
reviews
bindings
bibliographies
biographies (author, editor)
table of contents
footnotes
endnotes
critical introduction
appendices (contextual, editorial)
errata strips
publisher information
typography/font
stitching/glue
whitespace, gutters
watermark
end papers
title pages
section pages
copyright
images (photos, illustrations)
dedications
acknowledgments
I encouraged students to think about these elements as they began to to conceptualize their digital editions. Many or all of these features might need to be included in a digital edition, and the challenge was to think about how we might represent them digitally. I also gave a very brief introduction to some of the current tools and platforms available for building digital editions. In the afternoon, we worked through a “Site Audit” of some existing digital editions, and considered what worked (and what didn’t) in the digital editions that are currently available.
Slides for day 1:
Day 2 Overview
On day two, we focused on project management. Borrowing heavily from Jeremy Bogg‘s work, I talked about the importance of thinking of the project in terms of different phases. Then I introduced the ever-so-important “Scope Document”, and asked the students to spend some time conceptualizing their project(s) as a whole. I suggested that before beginning to implement (read: code) a digital project, one must consider the project from multiple perspectives and have a rock-solid scope document and technical / feature specification in place. Building a project in phases allows for an iterative process that keeps the project moving forward, without the too-often paralysis that faces digital humanities projects that suffer from scope creep (or, more often, scope explosion). Instead of starting to code an entire collected works, I argued, try starting with a small subset that can serve as a robust working model for the project as whole.
I provided a handout with a long list of questions to ask at each stage of the project. These questions are meant to serve as a guide for project planning (and, if you so choose, a grant application).
Phase 1: Strategy / Project Objectives
- What kind of edition are you creating? Why?
- Why is your project important?
- What’s already available?
- Who is your audience?
- What are the limitations of your project?
- What approach or methodology will the project follow?
- What are the major dates or milestones for key points?
- How will you determine whether your project has been successful?
Phase 2: Scope
- What features would you like to include in your edition?
- What tools and technologies will you use (Islandora/Drupal, Image Markup Tool, Simile Timeline, JUXTA)?
- What kinds of questions can you ask of your data using text analysis and data visualizations? (This will impact the platform and technology you choose)
- Do you have technical skills or will you be working with a developer?
- Who will be involved in the project, and what will their responsibilities be?
- What specific components are needed on the site? What technologies? Static HTML? Need dynamic content? Need a CMS? Need a custom web application or interactive features?
- What tools would you like your project to be compatible with? Is there a specific data format you will need to use?
Phase 3: Content
- Create a sitemap that will determine how content is categorized and contained within the overall structure of the site
- Inventory of content: what will you put on each page? In each section?
- What kinds of materials are you using? General description? File formats?
- What is the relationship among different pages, images, texts, tags, categories, etc?
- How will users interact with your content? (Search, manipulation, view?)
Phase 4: Design
- What do you want to communicate?
- What do you want users to remember?
- How do you want users to respond?
- What are some “benchmark” editions that might influence your design process? (Site Audit)
- What do you like about these designs? Why?
Slides for day 2:
Day 3 Overview
On Wednesday, we moved into some hands-on technical work, and had the opportunity to begin using the Islandora editing system for the first time. Islandora is an editing workflow that integrates a Fedora Commons backend with a Drupal front-end. EMiC is working in partnership with the great folks at UPEI to create a fully-functional editing toolkit that allows users to pull materials from the commons (housed in the Fedora repository) and edit them in a web-based environment. Alan Stanley was an invaluable asset, and the testing and editing process would not have run as smoothly as it did without his help on the ground. It seemed like every time we found a bug, Alan was able to step in and fix it almost immediately.
Here are a few screenshots of the system:
The login screen and home menu:
MODS metadata editing for a Book object:
Object Description page:

TEI Editor:
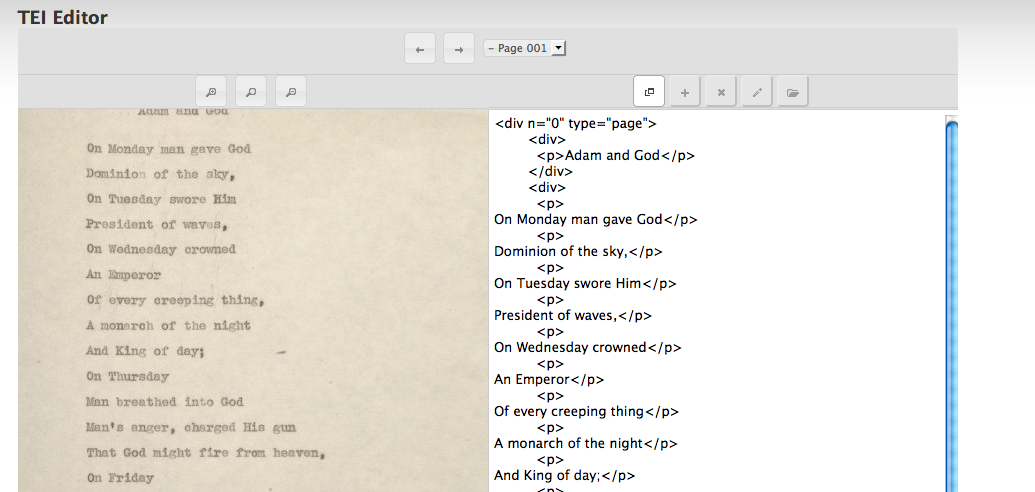

Image Markup Tool Integration:

The participants in the digital editions class showed remarkable patience and understanding working with a tool that, at its core, is still in alpha phase (pre-alpha, even). Thanks to everyone in the class for serving as the first user-testers for the Islandora editing suite. At times, I’m sure you felt more like bug hunters than editors, but please know that your feedback will be invaluable in the development of the EMiC/Islandora editing workflow. Kudos!
Day 4 Overview
Once we’d had a chance to work with some of the technical aspects of editing a digital edition, we took a step back and talked a bit about design. I argued that design is visual rhetoric, and that as editors, it is as important to think about aesthetics as it is to consider content. In fact, I would go so far as to say that in building digital editions, form and content are inseparable. Good design, built with the user-experience in mind, often means the difference between a usable and unusable tool. On the afternoon of day four, participants worked on various aspects of their projects, depending on what they deemed most important to them.
Slides for Day 4
Day 5 Overview
On Friday morning, each person in the class gave a brief presentation of their projects and what they learned this during the course. I think Yoshiko’s slide captures the week quite aptly:

Over the course of the week, the students worked through site audits and project scope documents, design specifications, user personas, and wireframes for their digital projects. We talked a lot about designing for the user experience and the importance of bringing together form and content. “Modularity” was certainly the word for the week, and I hope that the students left with a solid understanding of all of the various pieces (and people) that are part of the process of creating a digital edition. Thanks to all of the participants for your generosity, patience, engagement, and brilliance. I had a fabulous week, and I hope you did too!

February 17, 2011
How to Post a Blog to the EMiC Community
Have you been enjoying reading the EMiC Community blog? Do you want to post something of your own but are unsure of how to do so? This post will walk you step-by-step through the process of posting your first blog to the EMiC Community space.
When you visit any page on the EMiC Website, you’ll see a link to “Log in” at the top right of the page.
![]()
Click on this link you’ll be a taken to a page where you can enter your login details, which you will have received when you signed up as a member on the site. If you’ve forgotten your password, click on the “Lost your password?” link below the log in box.

Once you’re logged in, you’ll be taken to the user dashboard.
To post a blog entry, click on “New post” on the top right of your screen (or “Add new” under “Posts” on the left navigation bar). You’ll be redirected to the post entry page.

On the new post screen you’ll have the option (on the right) to choose to view a preview, save a draft, or publish your post. Your revision history will be listed at the bottom of the page. Your post won’t be visible on the public site until you click “Publish”.

You will also have the option to create categories and tags for your post. You can choose to place your post in the following categories: Training, Tutorials, News and Events, Research, and/or Technology.

You may also wish to create tags (or keywords) for your post. You can do this in the “Post Tags” box.

When you preview or view a post, you might find that you need to return to the editing screen. Any time you want to get back to the WordPress Dashboard when you’re logged in, you can click the link at the top right of your screen.
![]()
It’s really as easy as that! We encourage all of our members to use the blog as a forum for public dissemination of knowledge about all EMiC-related research and training. Your blog posts are a crucial means of communicating with project participants, partners, and the general public. We want to hear from you!!
Still have questions? Email me at mbtimney@uvic.ca.
February 15, 2011
Website Maintenance, 16 Feb. 2011, 7-9pm EST
The EMiC website will be undergoing some scheduled maintenance on 16 Feb. 2011 from 7-9pm EST. During that time you will be unable to access the site. Apologies in advance for the inconvenience.
November 19, 2010
EMiC and TILE: New Developments

Over the past few weeks, we’ve been in contact with Doug Reside at MITH, and are pleased to announce that EMiC and TILE have formed a partnership! Essentially what this means is that my time has been reallocated to the development and documentation of TILE, which is very exciting! This is just a preliminary announcement, and I’ll post more about this exciting venture soon!
August 3, 2010
Introducing: Anthologize!

The One Week | One Tool project, Anthologize, officially launched today at 12:30 ET, with 100+ people watching the live stream. I have say that I’m really impressed with the tool so far!
Below, I’ve compiled a list links to information, blogs, and groups pertaining to Anthologize (I will update as needed):
Official Sites
The Anthologize Homepage: http://anthologize.org/
Anthologize Google Group: http://groups.google.com/group/anthologize-users
The Official Launch Podcast: http://digitalcampus.tv/2010/08/03/episode-58-anthologize-live/
Cafe Press: http://www.cafepress.com/oneweekonetool
Blogs
Boone Borges: http://teleogistic.net/2010/08/introducing-anthologize-a-new-wordpress-plugin/
Dan Cohen, “Introducing Anthologize”: http://www.dancohen.org/2010/08/02/introducing-anthologize/
Dan Cohen’s Thoughts on One Week | One Tool: http://www.dancohen.org/2010/08/05/thoughts-on-one-week-one-tool/
Jana Remy: Daily Reports: 1 | 2 | 3 | 4 | 5 | 6 | Launch, or One Week | One Tool, Goes Live
Tom Scheinfeldt’s Lessons from One Week: Part 1: Project Management | Part 2: Tool Use | Part 3: Serendipity
Effie Kapsalis: Please Feed the Visitors | Smithsonian 2.0: Rapid Development at a 162 Year Old Institution
Kathleen Fitzpatrick: http://www.plannedobsolescence.net/anthologize/
Chad Black: http://parezcoydigo.wordpress.com/2010/08/03/anthologize-this-anthologize-that/
Mark Sample: http://www.samplereality.com/2010/08/04/one-week-one-tool-many-anthologies/
Anthologize at UMW: http://anthologize.umwblogs.org/
Julie Meloni @Profhacker: http://chronicle.com/blogPost/One-Week-One-Tool/25972
Patrick Murray-John: http://www.patrickgmj.net/blog/anthologize-uses-what-can-we-turn-on-its-head
Meagan Timney (My “Outsider’s Perspective”): http://corpora.ca/text/?p=422
News Items & Press
NEH Report:
http://www.neh.gov/ODH/ODHUpdate/tabid/108/EntryId/140/Report-from-ODH-Institute-One-Week-One-Tool.aspx
CUNY Commons: http://news.commons.gc.cuny.edu/2010/08/03/one-week-one-tool-the-reveal/
The Atlantic: http://www.theatlantic.com/science/archive/2010/08/academics-build-blog-to-ebook-publishing-tool-in-one-week/60852/
Musematic:
http://musematic.net/2010/08/03/anthologize/
Read-Write-Web: http://www.readwriteweb.com/archives/scholars_build_blog-to-ebook_tool_in_one_week.php
Chronicle Wired Campus: http://chronicle.com/blogPost/Digital-Humanists-Unveil-New/25966/
BookNet Canada Blog: http://booknetcanada.ca/index.php?option=com_wordpress&p=1787&Itemid=319
BBC Tech Brief: http://www.bbc.co.uk/blogs/seealso/2010/08/tech_brief_61.html
Snarkmarket: http://snarkmarket.com/2010/5979
Videos
Anthologize Test Drive by Ryan Trauman
—
I’ll finish with @sramsay‘s description of One Week | One Tool: “It was like landing on a desert island w/e.g. a master shipbuilder & someone who can start fires with their mind.” #oneweek
Please send additions and corrections to mbtimney.etcl@gmail.com or direct message @mbtimney
July 23, 2010
CFP: Scholarly Editing: The Annual of the Association for Documentary Editing
Just thought I’d pass along a relevant CFP from the Center for Digital Research in the Humanities:
See the original post at http://cdrh.unl.edu/opportunities/docediting_call.php
Background
Since 1979, Documentary Editing has been a premier journal in the field of documentary and textual editing. Beginning with the 2012 issue (to be published in late 2011), Documentary Editing will be renamed Scholarly Editing: The Annual of the Association for Documentary Editing and will become an open-access, digital publication. While retaining the familiar content of the print journal, including peer-reviewed essays about editorial theory and practice, the 2012 issue of Scholarly Editing will be the first to publish peer-reviewed editions.
CALL FOR EDITIONS
Even as interest in digital editing grows, potential editors have not found many opportunities to publish editions that fall outside the scope of a large scholarly edition. We believe that many scholars have discovered fascinating texts that deserve to be edited and published, and we offer a venue to turn these discoveries into sustainable, peer-reviewed publications that will enrich the digital record of our cultural heritage.
If you are interested in editing a small-scale digital edition of a single document or a collection of documents, we want to hear from you.
Proposals
We invite proposals for rigorously edited digital small-scale editions. Proposals should be approximately 1000 words long and should include the following information:
1) A description of content, scope, and approach. Please describe the materials you will edit and how you will approach editing and commenting on them. We anticipate that a well-researched apparatus (an introduction, annotations, etc.) will be key to most successful proposals.
2) A statement of significance. Please briefly explain how this edition will contribute to your field.
3) Approximate length.
4) Indication of technical proficiency. With only rare exceptions, any edition published by Scholarly Editing must be in XML (Extensible Markup Language) that complies with TEI (Text Encoding Initiative) Guidelines, which have been widely accepted as the de facto standard for digital textual editing. Please indicate your facility with TEI.
5) A brief description of how you imagine the materials should be visually represented. Scholarly Editing will provide support to display images and text in an attractive house style. If you wish to create a highly customized display, please describe it and indicate what technologies you plan to use to build it.
All contributors to Scholarly Editing are strongly encouraged to be members of the Association for Documentary Editing, an organization dedicated to the theory and practice of documentary and textual editing. To become a member, go to www.documentaryediting.org.
Please send proposals as Rich Text Format (RTF), MS Word, or PDF to the editors via email (agailey2@unlnotes.unl.edu, ajewell@unlnotes.unl.edu) no later than August 1, 2010 for consideration for the 2012 issue. After August 1, proposals will be considered for future issues. Feel free to contact us if you have questions.
CALL FOR ARTICLES
Scholarly Editing welcomes submissions of articles discussing any aspect of the theory or practice of editing, print or digital. Please send submissions via email to the editors (agailey2@unlnotes.unl.edu, ajewell@unlnotes.unl.edu) and include the following information in the body of your email:
Names, contact information, and institutional affiliations of all authors
Title of the article
Filename of article
Please omit all identifying information from the article itself. Send proposals as Rich Text Format (RTF), MS Word, or PDF; If you wish to include image files or other addenda, please send all as a single zip archive. Submissions must be received by February 1, 2011 for consideration for the 2012 issue. Please, no simultaneous submissions.
Thank you,
Amanda Gailey
Department of English
Center for Digital Research in the Humanities
University of Nebraska-Lincoln
agailey2@unlnotes.unl.edu
Andrew Jewell
University Libraries
Center for Digital Research in the Humanities
University of Nebraska-Lincoln
ajewell@unlnotes.unl.edu
July 12, 2010
TEI @ Oxford Summer School: Intro to TEI
Thanks to the EMiC project, I am very fortunate to be at the TEI @ Oxford Summer School for the next three days, under the tutelage of TEI gurus including Lou Burnard, James Cummings, Sebastian Rahtz, and C. M. Sperberg-McQueen. While I’m here, I’ll be providing an overview of the course via the blog. The slides for the workshop are available on the TEI @ Oxford Summer School Website.
In the morning, we were welcomed to the workshop by Lou Burnard, who is clearly incredibly passionate about the Text Encoding Initiative, and is a joy to listen to. He started us off with a brief introduction to TEI and its development from 1987 through to the present (his presentation material is available here). In particular, he discussed the relevance to the TEI to digital humanities, and its facilitation of the interchange, integration, and preservation of resources (between people and machines and between different media types in different technical contexts). He argues that the TEI makes good “business sense” for the following reasons:
As a learning exercise, we will be encoding for the Imaginary Punch Project, working through an issue of Punch magazine from 1914. We’ll be marking up both texts and images over the course of the 3-day workshop.
After Lou’s comprehensive summary of some of the most important aspects of TEI, we moved into the first of the day’s exercises: an introduction to oXygen. While I’m already quite familiar with the software, it is always nice to have a refresher, and to observe different encoding workflows. For example, when I encode a line of poetry, I almost always just highlight the line, press cmd-e, and then type a lower case “L”. It’s a quick and dirty way to breeze through the tedious task of marking-up lines. In our exercise, we were asked to use the “split element” feature (Document –> XML Refactoring/Split Element). While I still find my way more efficient for me, the latter also works quite nicely, especially if you’re using the shortcut key (visible when you select XML Refactoring in the menu bar).
Customizing the TEI
In the second half of the morning session, Sebastian provided an explanation of the TEI guidelines and showed us how to create and customize schemas using the ROMA tool (see his presentation materials). Sebastian explained that TEI encoding schemes consist of a number of modules, and each module contains element specifications. See the WC3 school’s definition of an XML element.
How to Use the TEI Guidelines
You can view any of these element specifications in the TEI Guidelines under “Appendix C: Elements“. The guidelines are very helpful once you know your way around them. Let’s look at the the TEI element, <author>, as an example. If you look at the specification for <author>, you will see a table with a number of different headers, including:
<author>
the name of and description of the element
Module
lists in which modules the element is located
Used By
notes the parent element(s) in which you will find <author>, such as in <analytic>:
<analytic>
<author>Chesnutt, David</author>
<title>Historical Editions in the States</title>
</analytic>
May contain
lists the child element(s) for <author>, such as “persName”:
<author persName=”Elizabeth Smart”>Elizabeth Smart</author>
Declaration
A list of classes to which the element belongs (see below for a description of classes).
Example and Notes
Shows some accepted uses of the element in TEI and any pertinent notes on the element. On the bottom right-hand side of the Example box, you can click “show all” to see every example of the use of <author> in the guidelines. This can be particularly useful if you’re trying to decide whether or not to use a particular element.
—
TEI Modules
Elements are contained within modules. The standard modules include TEI, header, and core. You create a schema by selecting various modules that are suited to your purpose, using the ODD (One Document Does it all) source format. You can also customize modules by adding and removing elements. For EMiC, we will employ a customized—and standardized—schema, so you won’t have to worry too much about generating your own, but we will welcome suggestions during the process. If you’re interested in the inner workings of the TEI schema, I recommend playing around with the customization builder, ROMA. I won’t provide a tutorial here, but please email me if you have any questions.
TEI Classes
Sebastian also covered the TEI Class System. For a good explanation what is meant by a “class”, see this helpful tutorial on programming classes (from Oracle), as well as Sebastian’s presentation notes. The TEI contains over 500 elements, which fall into two categories of classes: Attributes and Models. The most important class is att.global, which includes the following elements, among others:
@xml:id
@xml:lang
@n
@rend
All new elements are members of att.global by default. In the Model class, elements can appear in the same place, and are often semantically related (for example, model.pPart class comprises elements that appear within paragraphs, and the model.pLike class comprises elements that “behave like” paragraphs).
We ended with an exercise on creating a customized schema. In the afternoon, I attended a session on Document Modelling and Analysis.
If you’re interested in learning more about TEI, you should also check out the TEI by Example project.
Please email me or post to the comments if you have any questions.
July 7, 2010
THATCamp London: Day 2
**Cross-posted from my blog.**
We’re back up and running for day 2 of THATCamp London. After yesterday’s rather haphazard note-taking, I’ll try to be a bit more coherent today. That being said, I’m still writing “on-the-fly,” so please forgive any grammatical errors or shifts in verb tense.
I’m so excited that this is really still just the beginning of the Digital Humanities extravaganza! The main conference starts this afternoon, and the programme is jam-packed with interesting sessions. I’m presenting on Friday in a panel entitled, “Understanding the ‘Capacity’ of the Digital Humanities: The Canadian Experience, Generalised” with Ray Siemens, Michael Eberle-Sinatra, Lynne Siemens, Stéfan Sinclair, Susan Brown, and Geoffrey Rockwell (you can view the abstract here).
But back to today’s festivities. I am very happy to be sitting in on two “social web” sessions.
Session 1: Critical Mass in Social DH Applications
A fascinating and stimulating discussion on how to achieve critical mass in social applications and how to build DH communities. We began by looking at some of successful projects (namely Zotero, which has roughly ~1.5 million users; 300,000 daily users, and–in the commercial realm–Facebook and Twitter). As academics, we don’t think about marketing, but maybe it is something we need to learn. Our discussion ranged from finding an audience, getting people to use our applications, and getting input / encouraging participation from a large community. We discussed the importance of openness, and the necessity for aggregation of tools and services (which seems to be an ongoing theme at #thatcamp, at least in the sessions that I am attending).
Our main question was how we achieve critical mass in Digital Humanities. We determined that there are a few important factors in even starting to build a community, including:
– small group sharing
– low barriers
– carefully choosing a platform that will support the community
I talked a bit about our experience with the EMiC Online Community. While we didn’t have a lot of success with the first iteration of the social network (using Drupal), we learned from our mistakes and the new site with the wordpress back-end is working beautifully (thanks to @jcmeloni for all of her help getting things up and running, and to our participants who are blogging up a storm!).
See the Google Doc for the session.
Session 2: Outreach and Engagement
This session dove-tailed nicely with the previous one. Dan begins by discussing the 9/11 Digital Archive, a site for the cultural-social history of the day (~35, 000 contributors) that includes digital photographs, stories, video. He talks about the success of crowdsourcing as well as some interesting usage patterns for the project (including students who used the 9/11 archive for school projects, a general audience, a scholarly audience: historians, unsurprisingly, but also linguists who were studying teenage slang in the year 2000). Sometimes your unanticipated audience becomes your most powerful user group.
The session focused mostly on the importance of being aware of your users and how one goes about establishing user needs. I provided the example of our EMiC group at the Digital Humanities Summer Institute (DHSI) this past June. On the Sunday before the DHSI, the EMiC participants gathered together for a pre-institute meeting. We set everyone up with user accounts and encouraged them to blog on the EMiC website and tweet (@emic_project; hashtag: #emic) as much as possible during the institute. On the final day, we held a lunch meeting and got feedback. We came out with some fantastic ideas about how to promote the community space, and I think that the EMiC user testing serves as a great example for how we might enable and empower, on a small-scale at least, DH communities.
I think that usability testing is a crucial part of the outreach process, but as a group we agreed that it isn’t done as much as it should be. There are a number of ways to perform user testing, and if you don’t have a handful of testers at your fingertips, you can still get it done using professional services, such as those provided at usertesting.com, trymyui.com, or with the Silverback app. We also discussed the tension between a simple (or dumbed-down) interface and high-level functionality. Looking back to our previous session, it emerged that we should adhere to the principle of, as Dan said, “low walls, high ceilings.” I think that Google provides a great example of this (a topic for another post).
So, here are some of the take-home messages for building outreach and engagement into DH projects and applications:
– Interface: fast and simple, at least to start. A unified point of search is important. [Again: Google model]. This links back to our discussion in the previous session.
– We discussed how laypeople may not understand the potential of the data for computational methods. Dan suggested that the provision of a “recipe book” (tutorial) might help users discover higher-level functionality.*
– Importance of anticipating user needs (and building in a plan for unanticipated needs).
– Start small with an easy, entry point. Build outwards.
– Be critical, be proactive: Why do we want to do outreach? Who is our audience? Remember there will be an intended and unintended audience. The key is knowing what users need.
– Possible outreach solution: tap projects into public school curriculum objectives; provide lessons plans for teachers as part of your project.
We finished with a short discussion on the topic of training users / scholars. Again, I think this is something that EMiC does really well.
Other projects we discussed, at one point or another:
Library of Congress Flickr Stream
BAMBOO
DHSI
*I think the recipe book, in particular, is a great idea, and I invite EMiC participants, as well as other editors, to write their own research recipe (as a blog post to our EMiC Online Community. To sign up for a blog account, please email me).
Day 2 Wrap Up:
I really enjoyed the discussions at THATCamp today. Now it’s time to move from the pre-conference conference to the conference proper. I’m very much looking forward to the next few days!
See my THATCamp: Day 1 Report
July 6, 2010
THATCamp London: Day 1
**Cross-posted from my blog.**
Today is the first day of THATCamp London, and I can already feel my inner geek singing with joy to be back with the DH crowd. In the pre-un-conference coffee room, I met up with some friends from DHSI (hello Anouk and Matteo!). Here are my “written on the fly” conference notes (to borrow from Geoffrey Rockwell’s methodology for his DHSI conference report):
– We begin in a beautiful lecture hall, the KCL Anatomy Theatre and Museum. I already feel the intellectual juices flowing.
– Dan Cohen provides introductions and a history of THATCamp. Notes that unstructured un-conferences can be incredibly productive. (We are creating, synthesizing, thinking). He recalls that the first THATCamp was controlled chaos.
– Dan setting some ground rules. He is adamant, “It’s okay to have fun at THATCamp!” (Examples: A group at one THATCamp who played ARG with GPS, another created robotic clothing!)
– We are asked to provide a 30 second to 1 minute summary of the proposals before we vote. Other sessions are proposed as well. Looks like a great roundup.
Sessions related to my own research that I am interested in attending:
– social tools to bring researchers and practitioners together
– living digital archives
– Participatory, Interdisciplinary, and Digital
– critical mass in social DH applications
– visualization
In my mind, the winner of the best topic/session title is “Herding Archivists.”
The beta schedule of the conference is now up: http://thatcamplondon.org/schedule/
Session 1: Data for Social Networking
The main questions and ideas we consider:
– What kind of methods/tools are people using for analysing data?
– Ethical issues in data collection and gathering?
– How do you store ‘ephemeral’ digital content
– What do we want to find out from our social network data?
– What Tools for Social Network Interrogation and Visualization?
– Our wishlist for working with social network data …
You can also check out the comprehensive Google Doc for the session.
Session 2: Stories, Comics, Narratives
– Major issues: 1) Standards, 2) Annotation, 3) Visualization
– narratives and semantic technologies
– difficulty of marking up complex texts such as comic books, tv shows
– Dan Cohen, how might we go about standardizing or making available different documents? Is markup always the answer?
– One participant asks, does it matter what format the document is in as long as the content is there?
– Once again, standardization is a key question. Once the data is collected, shouldn’t it be made available?
– Question of IP and copyright is also raised, and generates some heated discussion.
– “Semantic Narratives” and the BBC’s Mythology Engine.
Session 3: Digital Scholarly Editions
– A productive round-table on the future of the digital scholarly edition.
– Major issues: standardization, resources, audience
For discussion notes, please see the Google Doc for the session.
Session 4: Using Social Tools for Participatory Research Bringing Researchers and Practitioners Together
– Framework for academics to connect
-Finding connections, drawing on enthusiasm and community: http://en.logilogi.org/#/do/logis and http://www.londonlives.com.
– We need tools that collate information and resources
See the Google Doc for the session.
All in all, it was a very productive day.
—
And just for fun: Doctor Who Subtitle Search (Thanks, Anouk!)
June 17, 2010
Summary of EMiC Lunch Meeting, June 11, 2010
On the final day of DHSI, EMiC participants gathered for an informal meeting to discuss their summer institute experiences and to plan for the upcoming year. Dean and Mila attended via Skype (despite some technical difficulties). We began by going around the table and talking about our week at DHSI. We reviewed the courses that we took, discussed our the most helpful aspects, and least. The participants who had taken the TEI FUNdamentals course agreed that the first few days were incredibly useful, but that the latter half of the course wasn’t necessarily applicable to their particular projects. Dean made the comment that we should pick the moments when we pay attention, and work on our material as much as possible. Anouk noted the feeling of achievement (problem-solving feedback loop), and her excitement at the geographical scope involved in mapping social networks and collaborative relationships as well as standard geographical locations. It sounds like everyone learned a lot!
We also agreed that there is a definite benefit in taking a course that also has participants who are not affiliated with EMiC; the expertise and perspective that they bring to the table is invaluable.
After our course summaries, we began to think about the directions in which we want to take EMiC. We discussed the following:
1. The possibility of an EMiC-driven course at DHSI next year, which I will be teaching in consultation with Dean and Zailig
a. The course will likely be called “Digital Editions.”
b. It will be available to all participants at the DHSI, but priority registration will be given to EMiC partipants.
c. It will include both theoretical and practical training in the creation of digital editions (primarily using the Image Markup Tool), but also including web design and interface models.
d. We will develop the curriculum based on EMiC participants’ needs (more on this below).
2. Continued Community-Building
The courses provided us with ideas of what we want to do as editors, and allowed us to see connections between projects. The question that followed was how we will work with one another, and how we sustain discussion.
a. We agreed that in relation to the community, how we work together and what our roles are is very important, especially as they related to encoding and archival practice.
b. We discussed how we would continue to use the blog after we parted ways at the end of the DHSI. Emily suggested that we develop a formalized rotational schedule that will allow EMiC participants at different institutions to discuss their work and research. We agreed that we should post calls for papers and events, workshop our papers, and use the commenting function as a means of keeping the discussion going. (Other ideas are welcome!)
c. We discussed other ways to solidify the EMiC community, and agreed that we should set up EMiC meetings at the different conferences throughout the year (MSA, Congress, Conference on Editorial Problems, etc).
3. What’s next?
a. For those of you who are interested in learning more about text encoding, I encourage you to visit the following sites:
• WWP Brown University: http://www.wwp.brown.edu/encoding/resources.html
• Doug Reside’s XML TEI tutorial: http://mith2.umd.edu/staff/dreside/week2.html
b. We are hoping that there will be an XSLT course at the DHSI next year.
c. Next year’s EMiC Summer Institute line-up will include 3 courses: TEMiC theory, TEMiC practice, and DEMiC practice.
d. Most importantly, we determined that we need to create a list of criteria: what we need as editors of Canadian modernist texts. Dean requested that everyone blog about next year’s EMiC-driven DHSI future course. Please take 15-20 minutes to write down your desiderata. If you can, please come up with something of broad enough appeal that isn’t limited to EMiC. (Shout out to Melissa for posting this already!)
As a side note, I spoke with Cara and she told me that there is indeed going to be a grad colloquium next year, which will take place on Tuesday, Wednesday, and Thursday afternoon during the DHSI. Look for a call for papers at the end of summer.
It was lovely to meet everyone, and I am looking forward to seeing you all soon!
**Please post to the comments anything I’ve missed. kthxbai.