Archives
Posts Tagged ‘digital humanities’
June 20, 2014
New in the Neighbourhood
This year was my first ever experience of DHSI in Victoria, and it has been an awesome whirlwind of activities — meeting so many great people and participating in a lot of the colloquium and “Birds of a Feather” sessions. If I were to sum up the experience in a few words, it might be something like “excited conflict”. There is so much to see and do that it’s a little difficult not to become physically drained and mentally overloaded in just a couple days. Yet, at the end of the week, and even now, I find myself wanting to return for another heavy dose of the same, and wishing it was just a little bit longer.
The Course
I participated in The Sound of Digital Humanities course with Dr. John Barber, along with a few fellow colleagues I work with on a poetry archive project back at UBCO. Throughout the week, the course itself weaved through different focuses, and in between practicing basic editing in Audacity and GarageBand, there was much deep discussion about the nature of sound, theory, research, copyright, and the like. It is especially the latter discussion portion that I was keenly interested in, as we found that some others in the class were doing projects based on or around archives, and were tackling questions and concerns similar to what pertained to our project. It was an opportunity to not only listen and glean some greater insights from experts and generally brilliant minds, but to reciprocate it and impart some of my knowledge to others for application towards their own projects. The general atmosphere is… infectious enthusiasm: everyone is quick to offer their own valuable experiences and suggestions for solutions for others peoples’ projects — in some cases right down to the nitty-gritty technical details. In fact, come to think of it, it doesn’t stray too far from what you might find at a typical medium-sized gathering at a web development conference: some give talks on new cool techniques and technologies, and everyone is engaged in vigorous talk of theory and stories and jokes about working in the field, even over a couple pints at the pub. It was that kind of coming together and collaboration in our class (sans alcohol) which culminated with each of us putting a bit of ourselves into a sound collage representative of the broader aims of the Digital Humanities and our nuanced experiences in it. It was all at times (sometimes simultaneously) hilarious and poignant. Definitely not something I will forget any time soon.
New in the Neighbourhood
In addition to meeting new acquaintances, the week was also a time of reunion, where I was able to reconnect with my colleagues on our poetry archive project. It was a helpful and fun time for us to “regroup” — to reflect on the project’s progress, and also come back with new energy in thinking about ways of moving forward, with the application of some of our discussions both in class and within the larger DHSI hub.. For me, Chris Friend’s presentation on crowd-sourced content creation and collaborative tools yielded wonderful points about the benefits and perils of using such a model pedagogically. It has made me more particularly sensitive to how pedagogical functions might be brought to our archive, and what designs we might create (both visually and technically) to accommodate that.
On a more personal front, attending DHSI (and by extension, learning about the Digital Humanities as a field this year) has solidified a deep sense of belonging for me through moments of glorious serendipity, if you will; of happening upon something fascinating at the end of a long wandering; of searching for a place to call my “intellectual” and “academic” home. It is a place that beautifully brings together my major pursuits of web development, literary theory/criticism, and music, and collectively articulates them as the makeup of “what I do”. It has been one of those somewhat rare “Ah-ha!” moments where you find something that you were looking for all along, but didn’t know quite what it was.
It’s been a wild ride, but one that I definitely want embark on again. My greatest thank yous, all of my friends and colleagues — old and new — for such a wonderful experience. I look forward to when I can return again for another week-long adventure and “geekfest”!
Keep it “robust” my friends.
June 12, 2014
What Makes It Work
As part of EMiC at DHSI 2014, I took part in the Geographical Information Systems (GIS) course with Ian Gregory. The course was tutorial-based, with a set of progressive practical exercises that took the class through the creation of static map documents through plotting historical data and georeferencing archival maps into the visualization and exploration of information from literary texts and less concrete datasets.
I have been working with a range of material relating to Canadian radical manifestos, pamphlets, and periodicals as I try to reconstruct patterns of publication, circulation, and exchange. Recently, I have been looking at paratextual networks (connections shown in advertisements, subscription lists, newsagent stamps, or notices for allied organizations, for example) while trying to connect these to real-world locations and human occupation. For this course, I brought a small body of material relating to the 1932 Edmonton Hunger March: (1) an archival map of the City of Edmonton, 1933 (with great thanks to Mo Engel and the Pipelines project, as well as Virginia Pow, the Map Librarian at the University of Alberta, who very generously tracked down this document and scanned it on my behalf); (2) organizational details relating to the Canadian Labor Defense League, taken from a 1933 pamphlet, “The Alberta Hunger-March and the Trial of the Victims of Brownlee’s Police Terror”, including unique stamps and marks observed in five different copies held at various archives and library collections; (3) relief data, including locations of rooming houses and meals taken by single unemployed men, from the City Commissoner’s fonds at the City of Edmonton Archives; and (4) addresses and locational data for all booksellers, newspapers, and newsstands in Edmonton circa 1932-33, taken from the 1932 and 1933 Henderson’s Directories (held at the Provincial Archives of Alberta, as well as digitized in the Peel’s Prairie Provinces Collection).
Through the course of the week I was able to do the following:
1. Format my (address, linguistic) data into usable coordinate points.
2. Develop a working knowledge of the ArcGIS software program, which is available to me at the University of Alberta.
3. Plot map layers to distinguish organizations, meeting places, booksellers, and newspapers.
4. Georeference my archival map to bring it into line with real-world coordinates.
5. Layer my data over the map to create a flat document (useful as a handout or presentation image).
6. Export my map and all layers into Google Earth, where I can visualize the historical data on top of present-day Edmonton, as well as display and manipulate my map layers. (Unfortunately, the processed map is not as sharp as the original scan.)
7. Determine the next stages for adding relief data, surveillance data, and broadening these layers out beyond Edmonton.
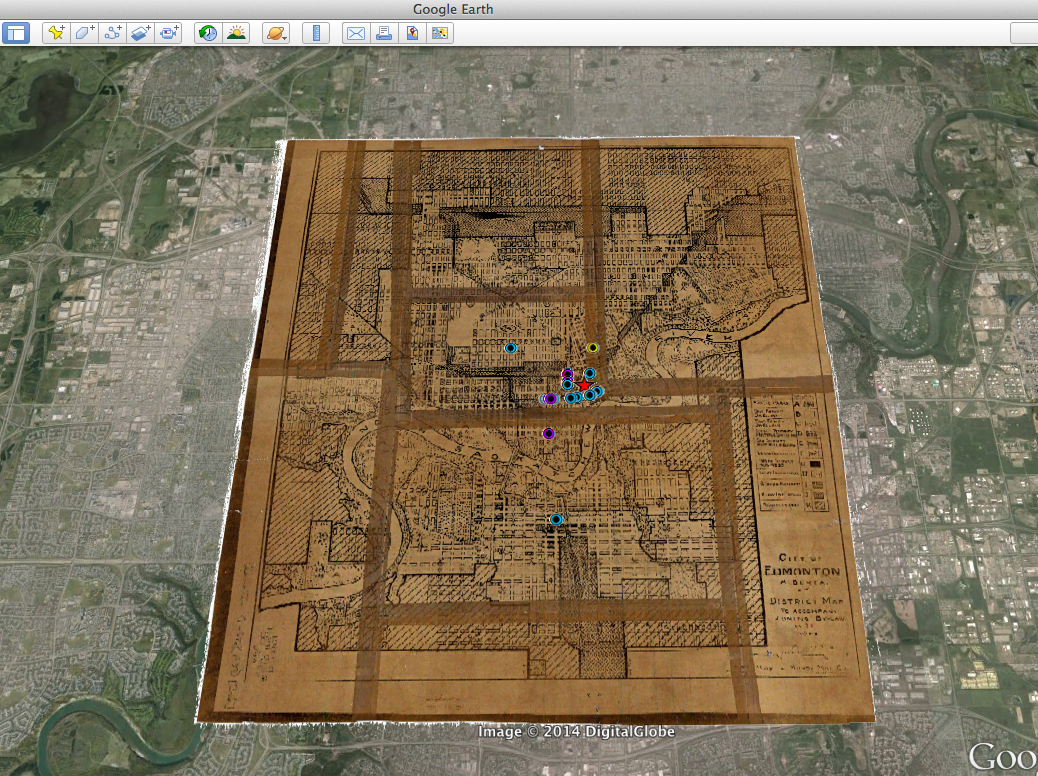
Archival map of City of Edmonton, 1933, georeferenced and overlaid into Google Earth imagery
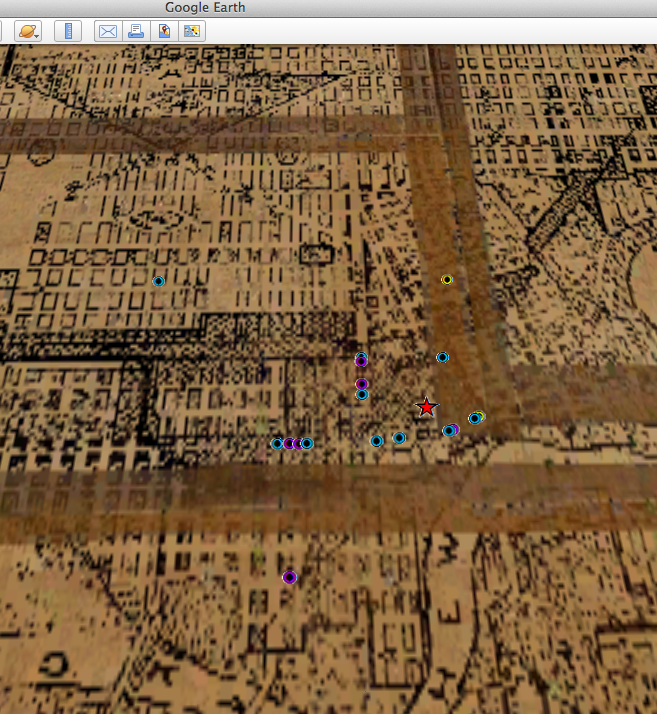
Detail: Archival map of City of Edmonton, 1933. Downtown area showing CLDL (red), booksellers (purple), newsstands (blue), and meeting places (yellow)
What I mean to say is, it worked. IT WORKED! For the first time in five years, I came to DHSI with an idea and some data, learned the right skills well enough to put the idea into action, and to complete something immediately usable and still extensible.
This affords an excellent opportunity for reflecting on this process, as well as the work of many other DH projects. What makes it work? I have a few ideas:
1. Expectations. Previous courses, experiments, and failures have begun to give me a sense of the kind of data that is usable and the kind of outcomes that are possible in a short time. A small set of data, with a small outcome – a test, a proof, a starting place – seems to be most easily handled in the five short days of DHSI, and is a good practice for beginning larger projects.
2. Previous skills. Last year, I took Harvey Quamen’s excellent Databases course, which gave me a working knowledge of tables, queries, and overall data organization, which helped to make sense of the way GIS tools operated. Data-mining and visualization would be very useful for the GIS course as well.
3. Preparation. I came with a map in a high-resolution TIFF format, as well as a few tables of data pulled from the archive sources I listed above. I did the groundwork ahead of time; there is no time in a DHSI intensive to be fiddling with address look-ups or author attributions. Equally, good DH work is built on a deep foundation of research scholarship, pulling together information from many traditional methods and sources, then generating new questions and possibilities that plunge us back into the material. Good sources, and close knowledge of the material permit more complex and interesting questions.
4. Projections. Looking ahead to what you want to do next, or what more you want to add helps to stymie the frustration that can come with DH work, while also connecting your project to work in other areas, and adding momentum to those working on new tools and new approaches. “What do you want to do?” is always in tension with “What can you do now?” – but “now” is always a moving target.
5. Collaboration. I am wholly indebted to the work of other scholars, researchers (published and not), librarians, archivists, staff, students, and community members who have helped me to gather even the small set of data used here, and who have been asking the great questions and offering the great readings that I want to explore. The work I have detailed here is one throughline of the work always being done by many, many people. You do not work alone, you should not work alone, and if you are not acknowledging those who work with you, your scholarship is unsustainable and unethical.
While I continue to work through this project, and to hook it into other areas of research and collaboration, these are the points that I try to apply both to my research practices and politics. How will we continue to work with each other, and what makes it work best?
April 8, 2014
Creating Your Own Digital Edition Website with Islandora and EMiC
I recently spent some time installing Islandora (Drupal 7 plus a Fedora Commons repository = open-source, best-practices framework for managing institutional collections) as part of my digital dissertation work, with the goal of using the Editing Modernism in Canada (EMiC) digital edition modules (Islandora Critical Edition and Critical Edition Advanced) as a platform for my Infinite Ulysses participatory digital edition.
If you’ve ever thought about creating your own digital edition (or edition collection) website, here’s some of the features using Islandora plus the EMiC-developed critical edition modules offer:
- Upload and OCR your texts!
- Batch ingest of pages of a book or newspaper
- TEI and RDF encoding GUI (incorporating the magic of CWRC-Writer within Drupal)
- Highlight words/phrases of text—or circle/rectangle/draw a line around parts of a facsimile image—and add textual annotations
- Internet Archive reader for your finished edition! (flip-pages animation, autoplay, zoom)
- A Fedora Commons repository managing your digital objects
If you’d like more information about this digital edition platform or tips on installing it yourself, you can read the full post on my LiteratureGeek.com blog here.
February 4, 2014
Where is the Nation in Digital Humanities?
Cross-posted from Postcolonial Digital Humanities
The organizers of the Postcolonial Digital Humanities site and the “Decolonizing Digital Humanities” panel at the most recent MLA have raised critically important questions about the intersection between postcolonial research and digital humanities work. In what ways, they ask, might the new tools and critical paradigms made possible by digital humanities transform postcolonial research and criticism? For instance, what becomes of the colonial archive and its relation to colonial and transnational knowledge production given the proliferation of new tools for archival research and cross-archival analysis? How might new methods of digital analysis offer opportunities to uncover buried colonial histories and expose present-day stereotypes and racism? How can new textual analysis tools remap literary canons to show the relevance of previously marginalized or ignored postcolonial texts? How do digital forms of activism and organization transform our understanding of cross-border solidarity? In what ways does this scholarly turn to the digital pave over local cultures and insist upon the English language as a requirement for membership in digital humanities?
Postcolonial theory and scholarship have always been about critiquing the manner in which the production of knowledge is complicit with the production of colonial relations and other relations of domination and exploitation. In this sense, postcolonial digital humanities work offers a timely and necessary investigation of the value of digital humanities to postcolonial studies. Reading the postcolonial through the digital, however discomfiting, enables scholars to make productive and unlikely connections between two methods direly in need of one another.
One element of the postcolonial that seems absent from a postcolonial digital humanities approach, however, is the continued salience of the nation as an organizing structure and category of analysis. Concern over the nation as the collective will of a people pervades postcolonial scholarship and Pheng Cheah has convincingly argued that “Postcolonial political domination and economic exploitation under the sign of capital and the capture of the people’s dynamism by neocolonial state manipulation signal the return of death. The task of the unfinished project of radical nationalism is to overcome this finitude” (229). Cheah is not, of course, yearning for a return to the days of blind nationalism or unproblematized collective identity of some postcolonial national vanguard. Rather, he acknowledges the failures of postcolonial nationalism to articulate a collective will for freedom while simultaneously demonstrating that “Radical literary projects of national Bildung remain cases of political organicism. They still endorse the idea that a radical national culture of the people contains the seeds for the reappropriation and transformation of the neocolonial state.” The true value of his intervention, in my eyes, is to remind us that the “national Bildung” in its various manifestations still remains a form by which a national culture can put ideas into practice and transform the state agencies that otherwise enable the practices of neocolonialism.
Like Bourdieu in his discussion of the left and right hands of the state, Cheah is unwilling to abandon the nation but sees it as a possible defense against neocolonial and neoliberal forms of domination. As such, postcolonial critics must remember that the “any project of emancipation however rational and realistic … necessarily presupposes the ability to incarnate ideals in the external world.” The nation provides, however flawed, a political framework and a series of material supports by which such projects may be put into practice.
Thinking of Cheah’s critique from a digital humanities perspective, I’m left wondering where is the nation in all of this digital humanities work? Certainly a great deal of our digital humanities scholarship is funded by our respective national institutions. My own work on Austin Clarke’s transnational modernism and the aesthetics of crossing is indirectly funded by the Social Sciences and Humanities Research Council of Canada through EMiC. In the US, the National Endowment of the Humanities funds HASTAC, the MLA, and countless other digital humanities projects. Yet despite its indebtedness to state institutions, digital humanities scholarship often appears to be practiced within a kind of transnational space unencumbered by any form of national culture.
Thus is seems to me that one important intervention that postcolonial digital humanities can offer is to ask how national forms persist within digital humanities scholarship? How does is the nation present, in however ghostly or marginal a form, within our digital humanities work? Does digital humanities work operate in a post-national space or is that (as Sylvia Soderlind argues in a Canadian context) just the latest form of nationalism?
I suggest that critics investigate the ways in which digital humanities research is subtly structured by the very state institutions that provide its funding. Tara McPherson has carefully traced the simultaneous and perhaps overlapping emergence of UNIX, object-oriented programming and contemporary forms of race thinking. A similar analysis needs to be performed concerning the indebtedness of digital humanities and critical code studies to the nations that produce these fields of analysis. Do digital humanities and nationalism inherit shared notions of humanism and if so how does that humanism structure our work? Does digital humanities occur in some transnational space, speaking across borders through the power of the internet? Or is our work invisibly yet meaningfully indebted and structured by the very state institutions that fund it?
What new forms of subjectivity does digital humanities make possible that circumvent the nation and what forms of subjection does this post-national positioning expose us to? Does digital humanities enable new forms of Cheah’s “radical nationalism” or is it an instance of something closer to Bauman’s liquid modernity: a transnational cultural practice that transcends the nation yet is accessible to only privileged elites physically and virtually jet setting across borders?
Cheah suggests that postcolonial critics, “instead of trying to exorcise postcolonial nationalism and replace it with utopian, liberal, or socialist cosmopolitanisms, … ought to address its problems in terms of the broader issue of the actualization of freedom itself.” These questions go beyond, I think, a politics of location and ask us to confront the national contexts of our work and how it might affect our own place in this struggle over “the actualization of freedom”. I think these are necessary questions for digital humanities that postcolonial digital humanities can begin to raise.
January 26, 2014
Experimental Editions: Digital Editions as Methodological Prototypes
Cross-posted from LiteratureGeek.com. An update on a project supported by an EMiC Ph.D. Stipend.
My “Infinite Ulysses” project falls more on the “digital editions” than the “digital editing” side of textual scholarship; these activities of coding, designing, and modeling how we interact with (read, teach, study) scholarly editions are usefully encompassed by Bethany Nowviskie’s understanding of edition “interfacing”.
Textual scholarship has always intertwined theory and practice, and over the last century, it’s become more and more common for both theory and practice to be accepted as critical activities. Arguments about which document (or eclectic patchwork of documents) best represents the ideal of a text, for example, were practically realized through editions of specific texts. As part of this theory through practice, design experiments are also a traditional part of textual scholarship, as with the typographic and spatial innovations of scholarly editor Teena Rochfort-Smith’s 1883 Four-Text ‘Hamlet’ in Parallel Columns.

How did we get here?
The work of McKerrow and the earlier twentieth-century New Bibliographers brought a focus to the book as an artifact that could be objectively described and situated in a history of materials and printing practices, which led to theorists such as McKenzie and McGann’s attention to the social life of the book—its publication and reception—as part of an edition’s purview. This cataloging and description eventually led to the bibliographic and especially iconic (visual, illustrative) elements of the book being set on the same level of interpretive resonance as a book’s linguistic content by scholars such as McGann, Tinkle, and Bornstein. Concurrently, Randall McLeod argued that the developing economic and technological feasibility of print facsimile editions placed a more unavoidable responsibility on editors to link their critical decisions to visual proof. Out of the bias of my web design background, my interest is in seeing not only the visual design of the texts we study, but the visual design of their meta-texts (editions) as critical—asking how the interfaces that impart our digital editing work can be as critically intertwined with that editing as Blake’s text and images were interrelated.
When is a digital object itself an argument?
Mark Sample has asked, “When does anything—service, teaching, editing, mentoring, coding—become scholarship? My answer is simply this: a creative or intellectual act becomes scholarship when it is public and circulates in a community of peers that evaluates and builds upon it”. It isn’t whether something is written, or can be described linguistically, that determines whether critical thought went into it and scholarly utility comes out of it: it’s the appropriateness of the form to the argument, and the availability of that argument to discussion and evaluation in the scholarly community.
Editions—these works of scholarly building centered around a specific literary text, which build into materiality theories about the nature of texts and authorship—these editions we’re most familiar with are not the only way textual scholars can theorize through making. Alan Galey’s Visualizing Variation coding project is a strong example of non-edition critical building work from a textual scholar. The Visualizing Variation code sets, whether on their own or applied to specific texts, are (among other things) a scholarly response to the early modern experience of reading, when spellings varied wildly and a reader was accustomed to holding multiple possible meanings for badly printed or ambiguously spelled words in her mind at the same time. By experimenting with digital means of approximating this historical experience, Galey moves theorists from discussing the fact that this different experience of texts occurred to responding to an actual participation in that experience. (The image below is a still from an example of his “Animated Variants” code, which cycles contended words such as sallied/solid/sullied so that the reader isn’t biased toward one word choice by its placement in the main text.)

Galey’s experiments with animating textual variants, layering scans of marginalia from different copies of the same book into a single space, and other approaches embodied as code libraries are themselves critical arguments: “Just as an edition of a book can be a means of reifying a theory about how books should be edited, so can the creation of an experimental digital prototype be understood as conveying an argument about designing interfaces” (Galey, Alan and Stan Ruecker. “How a Prototype Argues.” Literary and Linguistic Computing 25.4 (2010): 405-424.). These arguments made by digital prototypes and other code and design work, importantly, are most often arguments about meta-textual-questions such as how we read and research, and how interfaces aid and shape our readings and interpretations; such arguments are actually performed by the digital object itself, while more text-centric arguments—for example, what Galey discovered about how the vagaries of early modern reading would have influenced the reception of, for example, a Middleton play—can also be made, but often need to be drawn out from the tool and written up in some form, rather than just assumed as obvious from the tool itself.
To sign up for a notification when the “Infinite Ulysses” site is ready for beta-testing, please visit the form here.
Amanda Visconti is an EMiC Doctoral Fellow; Dr. Dean Irvine is her research supervisor and Dr. Matthew Kirschenbaum is her dissertation advisor. Amanda is a Literature Ph.D. candidate at the University of Maryland and also works as a graduate assistant at a digital humanities center, the Maryland Institute for Technology in the Humanities (MITH). She blogs regularly about the digital humanities, her non-traditional digital dissertation, and digital Joyce at LiteratureGeek.com, where this post previously appeared.
November 4, 2013
Infinite Ulysses: Mechanisms for a Participatory Edition
My previous post introduced some of my research questions with the “Infinite Ulysses” project; here, I’ll outline some specific features I’ll be building into the digital edition to give it participatory capabilities—abilities I’ll be adding to the existing Modernist Commons platform through the support of an EMiC Ph.D. Stipend.
My “Infinite Ulysses” project combines its speculative design approach with the scholarly primitive of curation (dealing with information abundance and quality and bias), imagining scholarly digital editions as popular sites of interpretation and conversation around a text. By drawing from examples of how people actually interact with text on the internet, such as on the social community Reddit and the Q&A StackExchange sites, I’m creating a digital edition interface that allows site visitors to create and interact with a potentially high number of annotations and interpretations of the text. Note that while the examples below pertain to my planned “Infinite Ulysses” site (which will be the most fully realized demonstration of my work), I’ll also be setting up an text of A.M. Klein’s at modernistcommons.ca with similar features (but without seeded annotations or methodology text), and my code work will be released with an open-source license for free reuse in others’ digital editions.
Features
So that readers on my beta “Infinite Ulysses” site aren’t working from a blank slate, I’ll be seeding the site with annotations that offer a few broadly useful tags that mark advanced vocabulary, foreign languages, and references to Joyce’s autobiography so that the site’s ways of dealing with annotations added by other readers can be explored. Readers can also fill out optional demographic details on their account profiles that will help other readers identify people with shared interests in or levels of experience with Ulysses.
On top of a platform for adding annotations to edited texts, readers of the digital edition will be able to:
1. tag the annotations
For Stephen’s description of Haines’ raving nightmare about a black panther, a reader might add the annotation “Haines’ dream foreshadows the arrival of main character Leopold Bloom in the story; Bloom, a Jewish Dubliner, social misfit, and outcast from his own home, is often described as a sort of ‘dark horse’“. This annotation can be augmented by its writer (or any subsequent reader) with tags such as “JoyceAutobiography” (for the allusions to Joyce’s own experience in a similar tower), “DarkHorses” (to help track “outsider” imagery throughout the novel), and “dreams”.
2. toggle/filter annotations both by tags and by user accounts
Readers can either hide annotations they don’t need to see (e.g. if you know Medieval Latin, hide all annotations translating it) or bring forward annotations dealing with areas of interest (e.g. if you’re interested in Joyce and Catholicism)
Readers can hide annotations added by certain user accounts (perhaps you disagree with someone’s interpretations, or only want to see annotations by other users that are also first-time readers of the book).
3. assign weights to both other readers’ accounts and individual annotations
As with Reddit, each annotation (once added to the text) can receive either one upvote or one downvote from each reader, by which the annotation’s usefulness can be measured by the community, determining how often and high something appears in search results and browsing. Votes on annotations will also accrue to the reader account that authored those annotations, so that credibility of annotators can also be roughly assessed.
3. cycle through less-seen and lower-ranked editorial contributions
To prevent certain annotations from never being read (a real issue unless every site visitor wishes to sit and rank every annotation!)
4. track of contentious annotations
To identify and analyze material that receives an unusual amount of both up- and down-voting
5. save private and public sets of annotations
Readers can curate specific sets of annotations from the entire pool of annotations, either for personal use or for public consumption. For example, a reader might curate a set of annotations that provide clues to Ulysses‘ mysteries, or track how religion is handled in the book, or represent the combined work of an undergraduate course where Ulysses was an assigned text.
I’m expecting that the real usage of these features will not go as planned; online communities I’m studying while building this edition all have certain organic popular usages not originally intended by the site creators, and I’m excited to discover these while conducting user testing. I’ll be discussing more caveats as to how these features will be realized, as well as precedents to dealing with heavy textual annotations, in a subsequent post.
First Wireframe

In the spirit of documenting an involving project, here’s a quick and blurry glance at my very first wireframe of the site’s reading page layout from the summer (I’m currently coding the site’s actual design). I thought of this as a “kitchen sink wireframe”; that is, the point was not to create the final look of the site or to section off correct dimensions for different features, but merely to represent every feature I wanted to end up in the final design with some mark or symbol (e.g. up- and down-voting buttons). The plan for the final reading page is to have a central reading pane, a right sidebar where annotations can be authored and voted up or down, and a pull-out drawer to the left where readers can fiddle with various settings to customize their reading experience (readers also have the option of setting their default preferences for these features—e.g. that they never want to see annotations defining vocabulary—on their private profile pages).
I’m looking forward to finessing this layout with reader feedback toward a reading space that offers just the right balance of the annotations you want handy with a relatively quiet space in which to read the text. This project builds from the HCI research into screen layout I conducted during my master’s, which produced an earlier Ulysses digital edition attempt of mine, the 2008/2009 UlyssesUlysses.com:

UlyssesUlysses does some interesting things in terms of customizing the learning experience (choose which category of annotation you want visibly highlighted!) and the reading experience (mouse over difficult words and phrases to see the annotation in the sidebar, instead of reading a text thick with highlightings and footnotes). On the downside of things, it uses the Project Gutenberg e-text of Ulysses, HTML/CSS (no TEI or PHP), and an unpleasant color scheme (orange and brown?). I’ve learned much about web design, textual encoding, and Ulysses since that project, and it’s exciting to be able to document these early steps toward a contextualized reading experience with the confidence that this next iteration will be an improvement.
Possibilities?
Because code modules already exist that allow many of these features within other contexts (e.g. upvoting), I will be able to concentrate my efforts on applying these features to editorial use and assessing user testing of this framework. I’ll likely be building with the Modernist Commons editing framework, which will let me use both RDF and TEI to record relationships among contextualizing annotations; there’s an opportunity to filter and customize your reading experience along different trajectories of inquiry, for example by linking clues to the identity of Bloom’s female correspondent throughout the episodes. Once this initial set of features is in place, I’ll be able to move closer to the Ulysses text while users are testing and breaking my site. One of the things I hope to do at this point is some behind-the-scenes TEI conceptual encoding of the Circe episode toward visualizations to help first-time readers of the text deal with shifts between reality and various reality-fueled unrealities.
Practical Usage
Despite this project’s speculative design (what if everyone wants to chip in their own annotations to Ulysses?), I’m also building for the reality of a less intense, but still possibly wide usage by scholars, readers, teachers, and book clubs. This dissertation is very much about not just describing, but actually making tools that identify and respond to gaps I see in the field of digital textual studies, so part of this project will be testing it with various types of reader once it’s been built, and then making changes to what I’ve built to serve the unanticipated needs of these users (read more about user testing for DH here).
To sign up for a notification when the “Infinite Ulysses” site is ready for beta-testing, please visit the form here.
Amanda Visconti is an EMiC Doctoral Fellow; Dr. Dean Irvine is her research supervisor and Dr. Matthew Kirschenbaum is her dissertation advisor. Amanda is a Literature Ph.D. candidate at the University of Maryland and also works as a graduate assistant at a digital humanities center, the Maryland Institute for Technology in the Humanities (MITH). She blogs regularly about the digital humanities, her non-traditional digital dissertation, and digital Joyce at LiteratureGeek.com, where parts of this post previously appeared.
October 26, 2013
What if we build a digital edition and everyone shows up?: “Infinite Ulysses”, Klein, and exploring complex modernisms together through participatory editions
An update on a project supported by an EMiC Ph.D. Stipend.
Digital humanities productions (editions, archives, or other digital engagements) are increasingly sites of broader participation in textual interpretation, with how to evoke and harness “meaningful” crowdsourcing becoming an increasingly urgent question to scholars seeking a more public humanities.

Elsewhere, I’ve discussed how borrowing the HCI (human-computer interaction) idea of “participatory design” can help digital humanities practitioners and their public audiences to mutual intellectual gain. As we use the Web to open the texts we study to a wider community of discussion, bringing in diverse knowledges and interpretive biases, I’m interested in how we can usefully structure the overabundance of information proceeding from public/crowdsourced contextual annotation of literary texts (contextual annotation means notes that give a context for a word, phrase, or other chunk of text, ranging from definitions of advanced vocabulary to more interpretive annotations). That is: my “Infinite Ulysses” project (one of several code/design projects forming my literature dissertation) is conceived as a speculative experiment: what if we build an edition and everyone shows up and adds their own annotations to the text, or asks and answers questions in the textual margins? When this quantity of voices is combined with an unusually complex text such as James Joyce’s Ulysses—or works developed in response to Joyce’s writing, as with A.M. Klein—how might we create a digital edition critical experience that adeptly handles not only issues of contextual annotation quantity but also quality?
In addition to improving the ability of EMiC scholars to share their editions of Canadian Modernists with a wider, more participatory audience, I will test the scholarly use of this interface with two specific texts—a short work by Canadian author A. M. Klein subsequent to his introduction to the works of James Joyce, and Joyce’s Ulysses. This dual testing will let me trace resonances and dissimilarities between the two writings, developing a better understanding of how Klein’s Modernism built on and diverged from his readings in Joyce. Juxtaposing these two works allows me to apply the wealth of existing theorizations and questions about a digital Ulysses to the work of a far-less-often digitally theorized Canadian author—an extremely useful knowledge transfer packaged with a reusable participatory editing interface. EMiC’s generous support of a year of my dissertational work (through one of its Ph.D. stipends) has not only made this scholarly work possible in a practical sense, it has pushed me to look beyond my comfort zone of discussing the Joycean hypertextual to think about how such theorizing can extend to similar works that link back to the node of Ulysses.
I’ve previously blogged about the overarching plans for my digital dissertation: about how I’ll be empirically user-testing both current and personal theories about textuality through code and design, and how I’m designing this building-as-scholarship towards helping everyone—textual scholars and the lay person—participate in our love for the nuances of a text’s materiality, history, and meaning. This post is about the first of my dissertation’s three coding projects: designing and coding an interface that allows a participatory, vibrant, contextualizing conversation around complex Modernist texts, with Ulysses being my main focus. Packed into one sentence, my research question for this first project is: What might we learn from crafting an interface to usefully curate quantity and quality of contextual annotation for complex Modernist digital editions (such as Ulysses), where the critical conversation is opened to the public? That’s a long sentence covering both more abstract and more concrete critical work, and I’ll be breaking it into manageable chunks with the rest of this post and those to follow.
“Infinite” annotations.
While there isn’t a complete scholarly digital edition of Ulysses yet published, that hasn’t kept Joycean scholars from anticipating issues that might arise with the eventual migration to digital space. Where the limitations of print space have in the past kept annotations of the text in check, what will happen when a digital platform allows the addition and navigation of infinite annotations? Can we migrate complex print hypertexts such as Ulysses to a digital space with socially multiplied annotations without, as Mark Marino wonders, “diminish[ing] the force of the book”:
Assuming it were possible, would the creation of a system that automatically makes available all the allusions, unravels all the riddles, and translates foreign languages normalize Joyce’s text? (Mark C. Marino, “Ulysses on Web 2.0: Towards a Hypermedia Parallax Engine”)
In Joyce Effects: On Language, Theory, and History, Derek Attridge similarly sees a risk in Ulysses‘ hypertextualization:
[Ulysses‘] cultural supremacy, and the scholarly efforts which reflect and promote that supremacy, have turned it into a text that confirms us in our satisfied certainties instead of one that startles and defies is and thus opens new avenues for thought and pleasure. It now reassures us of our place in what might otherwise seem a chaotic universe, or it provides a model of coherence to take a refuge in, a satisfying structure where the details all make sense… a spurious sense of rich complexity by reducing differences and distinctions (Derek Attridge, Joyce Effects: On Language, Theory, and History, 185)
Yet Attridge sees space for promise in the digital development of the text as well:
The very magnitude of the encyclopedic Joycean hypertext can itself be unsettling… and it may be possible to produce a hypermedia version of Ulysses that is anything but reassuring—one that revives, in new ways, the provocations and disturbances of the original publication… The best teachers (like the best critics) are those who find ways to sustain the disruptive force of Ulysses even while they do their necessary work of explaining and demystifying (Derek Attridge, Joyce Effects: On Language, Theory, and History, 186-188)
Despite there being no full digital edition of Ulysses against which to test these fears and assumptions, we already have some questions about what happens to a complex Modernist text when “everyone shows up”, and I’m hoping that by creating a site that experiments with allowing “infinite” contextual annotation of Ulysses (that’s where the “Infinite Ulysses” title of my project comes from), we can get a more realistic picture of what extreme annotation actually does to our experience of the text. When even someone as familiar with the text(s) as Ulysses editor Hans Walter Gabler can still learn new things about Ulysses (as he marveled during a class at the University of Victoria this summer), I’m confident that Ulysses will persist as always partially unfixed, always giving back more—and the Joycean digital theoretical work of Michael Groden and other digital humanists is ripe for carrying over to similarly complex Canadian texts.
Quantity and quality, signal and noise.
While the final effect of unlimited space to discuss and interpret the text remains to be seen, the “Infinite Ulysses” project will also tackle two more immediate problems: quality and quantity of annotation. If everyone is submitting annotations to a digital edition, how can we automate the massive task of curation and moderation of these annotations so that it occurs in a timely and unbiased manner? And once we’ve separated the wheat of critical yet diverse annotations from the chaff of repetitions, spam, and under-substantiated suggestions, how do we make the still-plentiful remaining material accessible to the users it would best serve? That is, how do we separate the signal from the noise when the “signal” of pertinent contextual annotations means different things for different reader needs?
So: what happens to a complex Modernist text when we allow “infinite” annotations on it, and how do we work with “infinite” annotations to filter, order, and display those annotations best suited to a given reader? In a future post on this blog, I will explain the specific features I’m coding into my digital edition interface to approach these questions.
To sign up for a notification when the “Infinite Ulysses” site is ready for beta-testing, please visit the form here.
Amanda Visconti is an EMiC Doctoral Fellow; Dr. Dean Irvine is her research supervisor and Dr. Matthew Kirschenbaum is her dissertation advisor. Amanda is a Literature Ph.D. candidate at the University of Maryland and also works as a graduate assistant at a digital humanities center, the Maryland Institute for Technology in the Humanities (MITH). She blogs regularly about the digital humanities, her non-traditional digital dissertation, and digital Joyce at LiteratureGeek.com, where parts of this post previously appeared.
September 25, 2011
Tales from the Rare Books Room – on recording, organizing, and sharing
I have only dipped my toes into the waters of digital humanism. But now that I’ve spent some time thinking about how to store, organized, and share digital information – and especially after a week of learning TEI at TEMiC – I want to learn how to swim. What follows is my roundup of the EMiC-funded RA project I recently finished. I hope that by offering some of the details about my project, we can start a discussion about tools, processes, and protocols for similar projects.
In January 2010, I began working as an RA for Dean Irvine, gathering information towards the annotations for edition of FR Scott’s poetry that he is co-editing with Robert G. May (Auto-Anthology: Complete Poems and Translations, 1918-84). I am a PhD candidate at McGill, and I was hired by Dean Irvine to examine holdings in the FR Scott collection, which is housed in the Rare Books Room here. Dean wanted me to record annotations in Scott’s books of English Language poetry; this was intended to help the editors make decisions about what to annotate in the edition. I was to be his eyes for this part of the project, sifting through hundreds of books to find what was useful, thus allowing Dean to get the information he needed while staying home in Halifax. It works out that being someone else’s eyes is a serious challenge, because the two sets of eyes happen to be attached to two different brains. Before I elaborate on this challenge, though, I’d like to explain what this recording of annotations involved.
There are two separate finding aids for the Scott collection. I only found out about the second because while working in the Rare Books Room one afternoon, I happened to ask to see a hardcopy of the finding aid I’d been working with (I had a scan, but it was not entirely legible). Scott’s books were donated to McGill in two groups: the contents of his Law Faculty office, which were given to the library shortly after his death; and his personal library from his home, which his widow donated in 1988. The first finding aid – the one I had from the beginning, which seems to correspond to Scott’s personal library — was drawn up in 1990, and there is a manuscript note on its title page, indicating that the list needs revision but is complete. For reasons that remain obscure, a second finding aid was drawn up in 1994; it, too, appears to contain books from the second donation, and makes no reference to a third donation (which would easily explain the new finding aid, but which I have no reason to believe occurred). There does not appear to be a finding aid for the Law office books; they are now sitting in boxes, uncatalogued, in the Rare Books room, because the Law Library decided they weren’t interested in them.
I have offered this detailed account of the collection’s provenance because it is the clearest way to explain the organizational challenges I was facing. Both finding aids contained material that I was being asked to examine, but they were organized differently: the first was grouped by genre and language, and organized alphabetically within those groups, making it relatively easy to pick out the English-language poetry. The second was strictly alphabetical, so that unless I was familiar with the author or title, it was difficult to know whether a work was poetry or prose. To complicate the matter further, Dean had requested that poetry from before 1880 be excluded from my search – this narrowed the field, but made it a bit difficult to spot unfamiliar early works which Scott owned in modern editions. Before I could even begin looking at the books, this data had to be sorted and organized. No mean feat, particularly when I began with documents that had been scanned – OCR, as we’re all aware, is imperfect enough to cause serious aggravation.
And this is where I learned that I have a lot to learn about being a digital humanist. I recorded my findings in Word, because that is what I am used to using to do my work. Not only was it difficult to turn the scanned document into a pretty Word document – it was also tough to organize the entries in Word. In hindsight, it would have been much better to work in Excel. Doing so would have prompted me to think harder about how the data would be used and could be sorted: in retrospect, I envision columns indicating whether there are annotations, ephemera, Scott’s signature, inscriptions from others, and so on, in addition to the kind of discursive analysis that I provided. This raises the important matter of considering, from the get-go, the best tools for the job and the best ways to use those tools.
A related problem, as I mentioned above, is the difficulty of being another person’s eyes. Although I knew the purpose of the information I was gathering, it was difficult for me to know what was important information, so I took note of almost everything. Again, in retrospect, I’m pretty sure that taking note of the inscriptions to Scott, particularly in books that were otherwise un-annotated, was not an effective use of my time. Ultimately, I spent 10 hours this summer creating an Excel sheet that contained almost everything but the inscriptions. Such retrospective claims are intended as a reminder to me—and I hope to you—of the importance of thinking through what information we really want to gather, and how it should be organized. (I do, however, have a complete record of who wrote what in Scott’s books of poetry… you know, just in case.) Naturally, there are also things I might have taken note of that I didn’t: I did not regularly take note of the condition of the book, but only noted particularly interesting cases. I can imagine that know whether a book looked read or not might, in the end, be helpful in deciding whether a perceived allusion to something in that book was real.
A final point about data sharing: though I was sometimes able to provide a discursive account of an annotation, often it was necessary to have the pertinent page (or the ephemera) scanned. McGill’s Rare Books room does not have self-service scanning; each scan costs 25 cents, there is a limit of 10 scans per book, and a detailed scan form had to be completed to order the scan. Each image is returned as its own unique jpg with an incomprehensible numeric file name. So, when I had multiple scans from the same book, I needed to convert them to pdfs, combine them, and re-name the file so that it could be clearly associated with the book which it represented. Then, I had to upload those files to google docs, so they could be shared with Dean. All of this made for a really cumbersome process – one which I hope it might be possible to streamline should a similar case arise in the future. Perhaps it’s even possible to do this better now, but I’m just not aware of the tools to do it.
So… that’s what I’ve been up to. I hope that this narrative will be useful in helping other members of this community think about how we gather, organize, store, and share information. If there are tools out there that would have helped with this work, I’d love to hear about them… and I’d really like to hear your ideas about how we can plan a project so that we are using the available tools to their best advantage from the get-go. And in the meantime, I’m looking forward to signing up for more swimming lessons.
April 21, 2011
What the Digital Humanities Needs to Learn from Turbotax
On June 9, 2010, Wired.com ran a story announcing the intention of DARPA, the experimental research arm of the United States Department of Defense, to create “mission planning software” based on the popular tax-filing software, Turbotax.
What fascinated the DoD was that Turbotax “encoded” a high level of knowledge expertise into its software allowing people with “limited knowledge of [the] tax code” to negotiate successfully the complex tax-filing process that “would otherwise require an expert-level” of training (Shachtman). DARPA wanted to bring the power of complex “mission planning” to the average solider who might not have enough time/expertise to make the best decision possible for the mission.
I start with this example to show that arcane realms of expertise, such as the U.S. Tax Code, can be made accessible to the general public through sound interface design and careful planning. This is especially pertinent to Digital Humanities scholars who do not always have the computer-science training of other disciplines but still rely on databases, repositories, and other computer-mediated environments to do their work. This usually means that humanities scholars spend hours having awkward phone conversations with technical support or avoid computer-mediated environments altogether.
With the arrival of new fields like Periodical Studies, however, humanities scholars must rely on databases and repositories for taxonomy and study. As Robert Scholes and Clifford Wulfman note in Modernism in the Magazines, the field of periodical studies is so vast that editors of print editions have had to make difficult choices in the past as to what information to convey since it would be prohibitively expensive to document all information about a given periodical (especially since periodicals tended to change dramatically over the course of their runs). Online environments have no such limitations and thus provide an ideal way of collecting and presenting large amounts of information. Indeed, Scholes and Wulfman call for “a comprehensive set of data on magazines that can be searched in various ways and organized so as to allow grouping by common features, or sets of common features” (54).
What DARPA and Turbotax realize is that computer-mediated environments can force submission compliance with existing “best practices” in order to capitalize on the uneven expertise levels of the general population. Wulfman and Scholes call for the creation of a modernist periodical database where modernist scholars can work together and map the field of periodical studies according to agreed upon standards of scholarship. By designing a repository on a Turbotax model of submission compliance, the dream of community-generated periodical database that conforms to shared bibliographic standards is readily attainable.
Because of the vastness of its subject matter, Periodical Studies is inherently a collaborative discipline—no one scholar has the capacity to know everything about every periodical (or everything about one magazine for that matter). Thus, the creation of periodical database is necessary to map the field and gather hard data about modernist periodical production. The problem is that not every periodical scholar has the computer expertise to create or even navigate the complexities of database/repository systems. Nor does every scholar know how to follow the best metadata and preservation practices of archival libraries. We are now at a point where we can utilize the interests and expertise of humanities by creating a repository that forces proper “input” along the lines of Turbotax.
Challenge
I use the example of periodical studies to challenge the greater field of Digital Humanities. Our discipline has now reached a mature age, and think we can all agree that the battle between “Humanities Computing” and “Digital Humanities” should be put to rest as we move into the next phase of the field: designing user-friendly interfaces based on a Turbotax model of user input. For example, even at this stage of Digital Humanities, there doesn’t appear to be a web-based TEI editor that can link with open repositories like Fedora Commons. In fact, the best (and most stable) markup tool I’ve used thus far is Martin Holmes’s Image Markup Tool at the University of Victoria. Even this useful bit of software is tied to the Windows OS, and it operates independently of repository systems. That means a certain level of expertise is needed to export the IMT files to a project’s repository system. That is, the process of marking up the text is not intuitive for a project that wishes to harness the power of the many in marking up texts (by far, the most time-consuming process of creating a digital edition). Why not create a Digital-Humanities environment that once installed on a server, walks a user through the editing process, much like Turbotax walks a user through his/her taxes? I used to work as an editor for the James Joyce Quarterly. I experienced many things there, but the most important thing I learned is that there is a large community of people (slightly insane), who are willing to dedicate hours of their time dissecting and analyzing Joyce. Imagine what a user-generated Ulysses would look like with all of that input! (we would, of course, have to ban Stephen Joyce from using it–or at least not tell him about it).
Digital Humanities Ecosystems
The story of Digital Humanities is one littered with failed or incomplete tools. I suspect, save for the few stalwarts working under labs like Martin Holmes, or our colleagues in Virginia and Georgia, and elsewhere, that tools are dependent on stubborn coders with enough time to do their work. I find this to be a very inefficient way of designing tools and a system too dependent on personalities. I know of a handful of projects right now attempting to design a web-based TEI editor, but I’m not holding my breath for any one of them to be finished soon (goals change, after all). Instead of thinking of Digital Humanities development in these piecemeal terms, I think we need to come together as a federation to design ECOSYTEMS of DH work–much like Turbotax walks one through the entire process of filing taxes.
I think the closest thing we have to this right now is OMEKA, which through its user-base grows daily. What if we took Omeka’s ease-of-use for publishing material online and made into a full ingestion and publication engine? We don’t need to reinvent the wheel after all: Librarians have already shown us how we should store our material according to Open Archival Standards. There is even an open repository system in Fedora Commons. We even know what type of markup we should be using: TEI and maybe RDF. And Omeka has shown us how beautiful publication can be on the web.
Now, Digital Humanists, it is our time to take this knowledge and create archives/databases based on the Turbotax model of doing DH work: We need to create living ecosystems where each step of digitizing a work is clearly provided by a front end to the repository. Discovery Garden is working on such an ecosystem right now with the Islandora framework (a Fedora Commons backend with a Drupal front end), and I hope it will truly provide the first “easy-to-use” system that once installed on a server will allow all members of a humanist community to partake in digital humanities work. If I’m training students to encode TEI, why can’t I do so online actually encoding TEI for NINES or other projects? I’ve been in this business for years now, and even I get twitchy running shell scripts—my colleagues and students are even more nervous. So let’s build something for them, so we they can participate in the digital humanities as well. Everyone has something to gain.
I am attempting to harness the power of the crowd with “the Database of Modernist Periodicals,” to be announced this summer. I’ll let you know how it goes.
I end with this caveat: We need to prepare for the day when the “digital” humanities will simply be “the humanities,” and that means democratizing the digital (especially in our tools). Even I was able to file my taxes this year.
August 23, 2010
TEI & the bigger picture: an interview with Julia Flanders
I thought those of us who had been to DHSI and who were fortunate enough to take the TEI course with Julia Flanders and Syd Bauman might be interested in a recent interview with Julia, in which she puts the TEI Guidelines and the digital humanities into the wider context of scholarship, pedagogy and the direction of the humanities more generally. (I also thought others might be reassured, as I was, to see someone who is now one of the foremost authorities on TEI describing herself as being baffled by the technology when she first began as a graduate student with the Women Writers Project …)
Here are a few excerpts to give you a sense of the piece:
[on how her interest in DH developed] I think that the fundamental question I had in my mind had to do with how we can understand the relationship between the surfaces of things – how they make meaning and how they operate culturally, how cultural artefacts speak to us. And the sort of deeper questions about materiality and this artefactual nature of things: the structure of the aesthetic, the politics of the aesthetic; all of that had interested me for a while, and I didn’t immediately see the connections. But once I started working with what was then what would still be called humanities computing and with text encoding, I could suddenly see these longer-standing interests being revitalized or reformulated or something like that in a way that showed me that I hadn’t really made a departure. I was just taking up a new set of questions, a new set of ways of asking the same kinds of questions I’d been interested in all along.
I sometimes encounter a sense of resistance or suspicion when explaining the digital elements of my research, and this is such a good response to it: to point out that DH methodologies don’t erase considerations of materiality but rather can foreground them by offering new and provocative optics, and thereby force us to think about them, and how to represent them, with a set of tools and a vocabulary that we haven’t had to use before. Bart’s thoughts on versioning and hierarchies are one example of this; Vanessa’s on Project[ive] Verse are another.
[discussing how one might define DH] the digital humanities represents a kind of critical method. It’s an application of critical analysis to a set of digital methods. In other words, it’s not simply the deployment of technology in the study of humanities, but it’s an expressed interest in how the relationship between the surface and the method or the surface and the various technological underpinnings and back stories — how that relationship can be probed and understood and critiqued. And I think that that is the hallmark of the best work in digital humanities, that it carries with it a kind of self-reflective interest in what is happening both at a technological level – and it’s what is the effect of these digital methods on our practice – and also at a discursive level. In other words, what is happening to the rhetoric of scholarship as a result of these changes in the way we think of media and the ways that we express ourselves and the ways that we share and consume and store and interpret digital artefacts.
Again, I’m struck by the lucidity of this, perhaps because I’ve found myself having to do a fair bit of explaining of DH in recent weeks to people who, while they seem open to the idea of using technology to help push forward the frontiers of knowledge in the humanities, have had little, if any, exposure to the kind of methodological bewilderment that its use can entail. So the fact that a TEI digital edition, rather than being some kind of whizzy way to make bits of text pop up on the screen, is itself an embodiment of a kind of editorial transparency, is a very nice illustration.
[on the role of TEI within DH] the TEI also serves a more critical purpose which is to state and demonstrate the importance of methodological transparency in the creation of digital objects. So, what the TEI, not uniquely, but by its nature brings to digital humanities is the commitment to thinking through one’s digital methods and demonstrating them as methods, making them accessible to other people, exposing them to critique and to inquiry and to emulation. So, not hiding them inside of a black box but rather saying: look this, this encoding that I have done is an integral part of my representation of the text. And I think that the — I said that the TEI isn’t the only place to do that, but it models it interestingly, and it provides for it at a number of levels that I think are too detailed to go into here but are really worth studying and emulating.
I’d like to think that this is a good description of what we’re doing with the EMiC editions: exposing the texts, and our editorial treatement of them, to critique and to inquiry. In the case of my own project involving correspondence, this involves using the texts to look at the construction of the ideas of modernism and modernity. I also think the discussions we’ve begun to have as a group about how our editions might, and should, talk to each other (eg. by trying to agree on the meaning of particular tags, or by standardising the information that goes into our personographies) is part of the process of taking our own personal critical approaches out of the black box, and holding them up to the scrutiny of others.
The entire interview – in plain text, podcast and, of course, TEI format – can be found on the TEI website here.